CONTACT US
6 Steps to Activate the Value of Text to Graph Machine Learning Systems
This blog will walk through how to construct a text to graph machine learning pipeline to bring the power of text data and graphs together. Harmonizing these two techniques provides the next step in the evolution of machine learning as Natural Language Processing (NLP) and Graph Theory which have remained two of the fastest-growing fields within data science for the last several years.
Why Text to Graph Machine Learning?
There are lots of reasons, but the main one is NLP effectiveness. While these two domains can operate independently of one another, because of the value that graph brings to NLP, a natural question emerges about how to leverage the value of graph machine learning to uniquely drive more value from textual documents into a graph machine learning model. Text to graph machine learning is also a fundamental building block for how to create a knowledge graph, which is becoming a more and more important topic every year.
Check out a powerful new natural language interface to your graph database / knowledge graph that enables your non-technical users to ask natural language questions right to the database itself (meet Sherlock™ from Graphable).
Text Embeddings
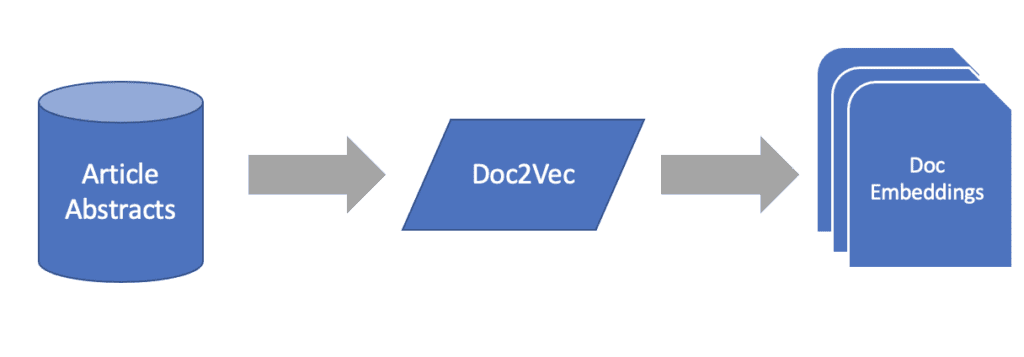
Before we can infuse our graphs with the information from our text, we must first extract the stored meaning and value from them. To do this we will implement a simple embedding model to produce feature vectors for each instance of text. This could be for individual words as would be the case if we were analyzing individual keywords from medical publications or even entire documents if we were interested in comparing the abstracts and meaning of publications or other documents.
In this example, we’ll assume we are interested in understanding how different publications relate to one another based on the text of their abstracts and their related network of co-authors.
We could do this with a number of different models or services, below I’ve listed a handful of the most common:
- TF-IDF
- Word2Vec
- BERT
Document Embeddings
- Doc2Vec
- AWS SageMaker Object2Vec
- Word Mover’s Embedding (WME)
- SBERT
Now that we have our document embeddings established, we can examine the graph machine learning portion of our problem.
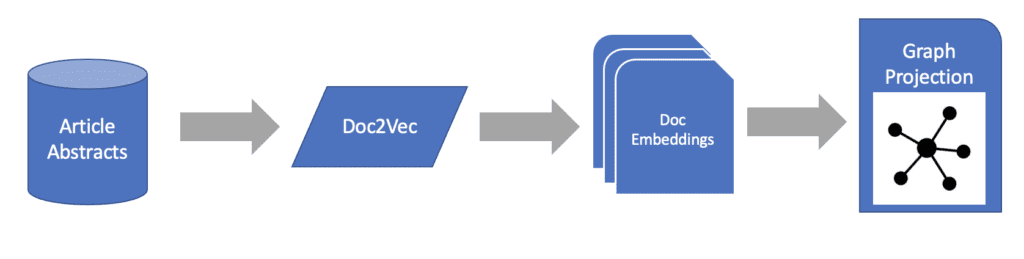
Setting the Stage with the Proper Projection
Before we can start training our graph ML model with our document embeddings, we first must describe the projection of the graph which it will train on. If you read our article What Is a Knowledge Graph, you will see that the native graph data store you’re using may contain several node types in addition to articles and authors, many of which could be connected to those articles and authors. Because of this, we must first distill our graph data into those nodes and relationships which are relevant to the problem at hand.

We begin by ignoring the rest of the knowledge graph to focus exclusively on author nodes, article nodes, and the relationships which connect them to get a bipartite projection of our graph
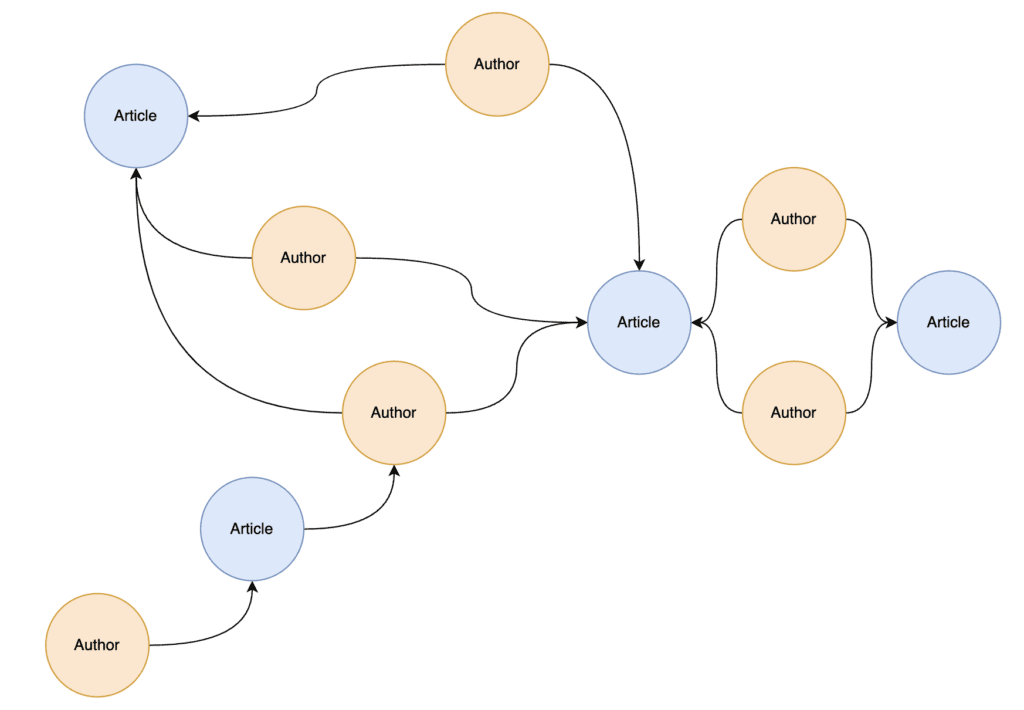
Next, we define a relationship weight to indicate which relationships are stronger than others, then we will “fold” this bipartite graph into a monopartite graph of articles where the weight of each relationship is governed by the number of co-authors two articles share.

Next, with our projection established, we’re to consider which graph ML model to use in our text to graph machine learning pipeline.
Choosing a Graph Machine Learning Model
Now that we have our publication data represented in an embedding space, and our graph projection established, we can start to think about how to feed it downstream to a graph machine learning model. However, not just any graph ML model will do, we must consider those which can accept a set of feature vectors.
Many of the early graph ML models that use topological adjacency or random walks to produce similarity measures exclusively rely on the connections between sets of nodes to produce vector representation of each node in the graph. Since these methods do not utilize any underlying node features in their calculations, they are ill-suited for the task at hand. Instead, we must rely on those model architectures which accept node features as part of their design. Once again, I’ve listed some popular options for such a task:
- Graph Convolutional Network (GCN)
- GraphSAGE
- Graph ATtention Network (GAT)
In our example, we’ll use GraphSAGE in our text to graph machine learning pipeline. (See our related article on Convolutional Graph Neural Networks)
Finally, with our model architecture selected, we can begin to train and get some results.
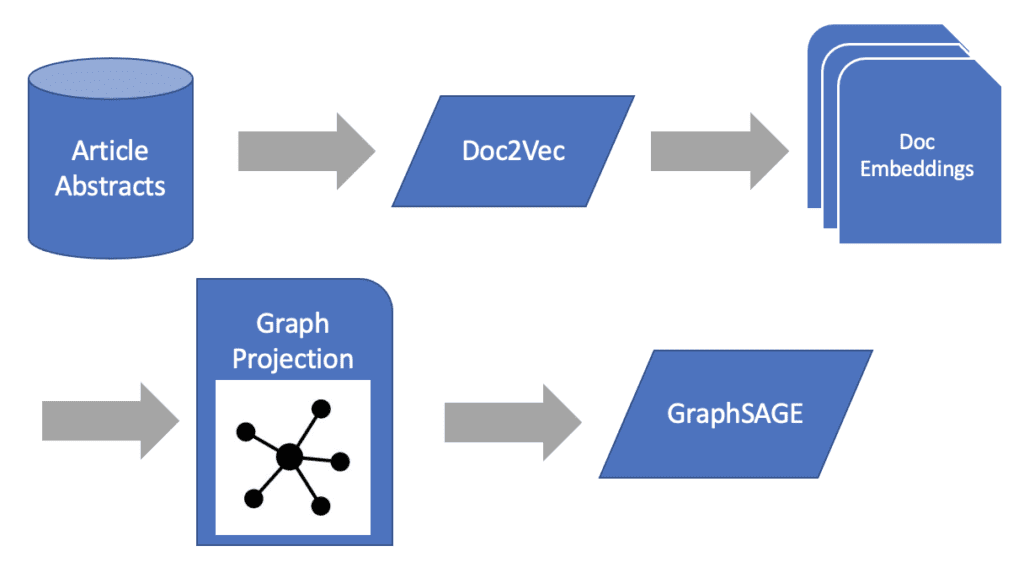
Passing Text to Graph Machine Learning Models
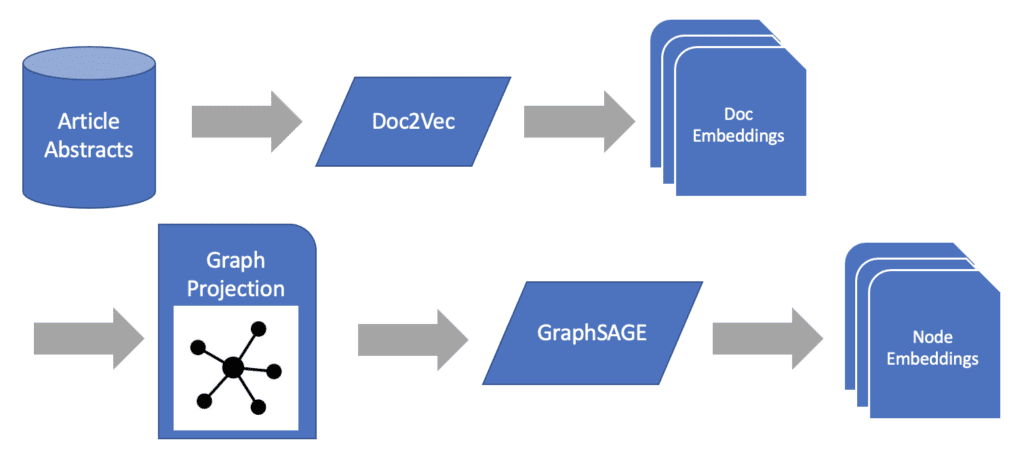
In order to capture both the document similarity and co-authorship network similarity in our documents let’s complete our text to graph machine learning pipeline by creating node representations for each of our documents.
First, let’s make sure our monopartite projection contains all the document embeddings we created earlier as node features.
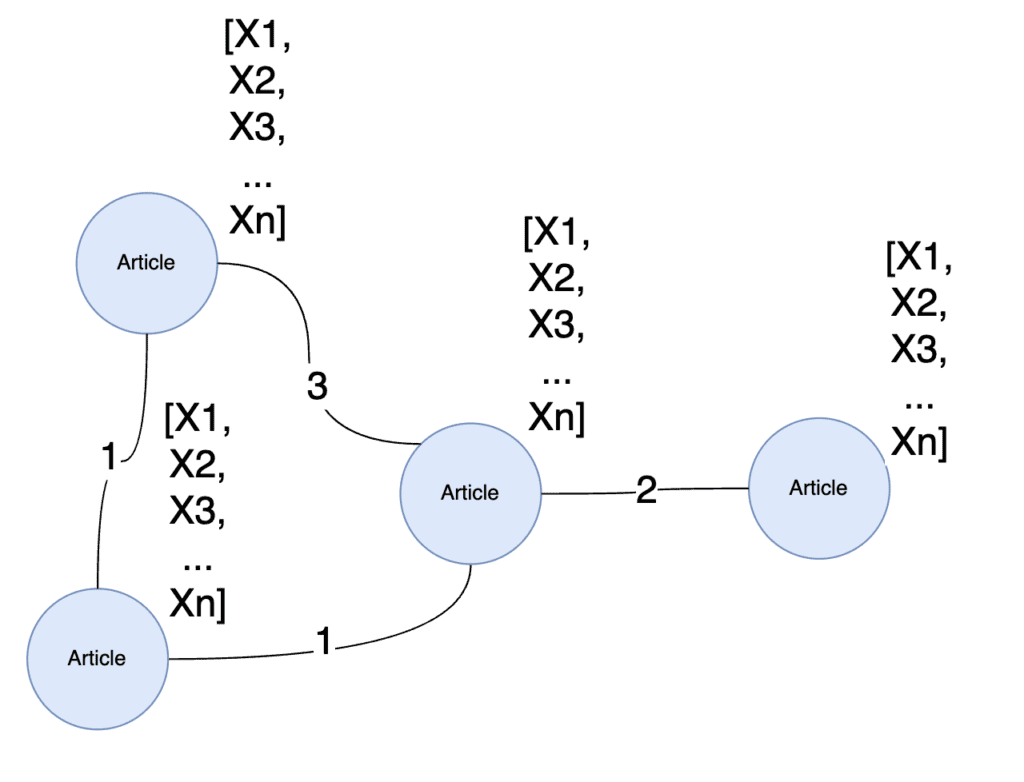
Next, we’ll train our GraphSAGE model against the projection with K = 2 to restrict the message passing to two degrees of separation. This should give us a stable message-passing flow between articles.
This message-passing architecture will cause any articles which are connected to one another to share their feature information between one another. Through this, we are passing the information captured by the document embedding model to other documents based on the number of authors they’ve shared. This information passing will then extend to other neighbors, as well as their neighbors, to develop the embedding space which will contain our final representations of the articles.
Utility of Text Powered Machine Learning
With our embeddings established we now have a collection of documents represented as vectors using both their underlying text similarity and co-authorship connectivity. This provides us with a set of extremely informed embeddings which can be used for a number of downstream tasks. Lets explore a few.
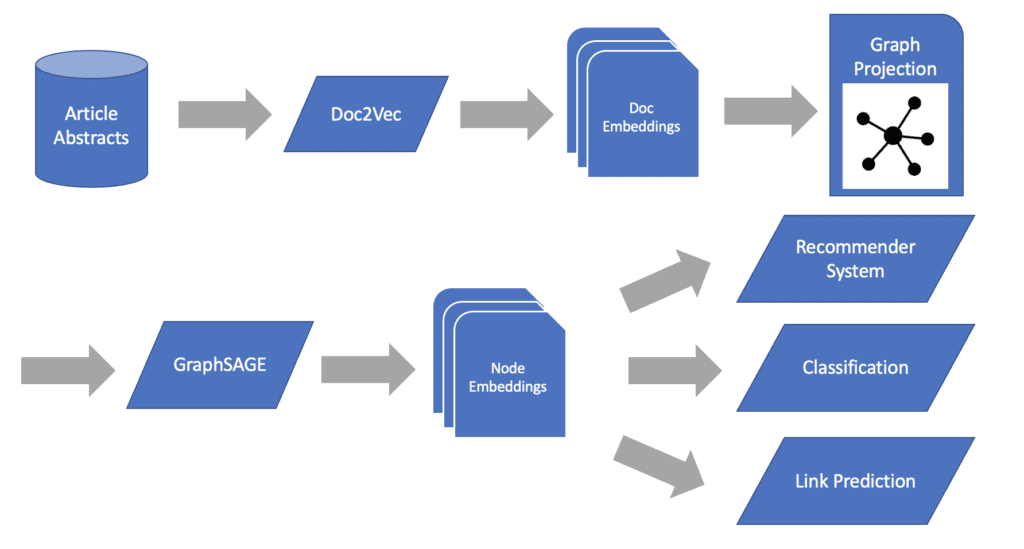
Clustering for Recommender Systems
While the simplest of any option, a simple KNN cluster allows us to also measure which documents are most similar to one another within the embedding space. Using this measure, we can easily supply a “Top N” recommendation based on the nearest neighbors for a given article.
Classification
One of the most powerful final tasks for our text to graph machine learning pipeline is feeding our embeddings to a final classifier model such as logistic regression, random forest, or XGBoost. This would allow us to use historical labels to classify which subject a given article may be associated with.
Link Prediction
Lastly, we can look to predict non-existing relationships within our graph. In this context, we could use it for link prediction when it comes to finding sets of authors who may want to consider doing research together in the future.
Conclusion
While text to graph machine learning is not the only way to accomplish NLP, it is rapidly becoming the most effective and valuable due to the unique strengths of the graph database. By combining the unique value of both fields, there is now a more powerful and scalable way to drive value from all your textual data.
If you are looking for more on graph NLP-related topics, check out our natural language is structured data article, or our post on the order of steps in natural language understanding. Also, for more on graph data science in general read this linked article.
Read Related Data Science / AI / LLM Articles:
- What are Graph Algorithms?
- Conductance Graph Community Detection: Python Examples
- What is Neo4j Graph Data Science?
- What is ChatGPT? A Complete Explanation
- ChatGPT for Analytics: Getting Access & 6 Valuable Use Cases
- Domo custom apps using Domo DDX Bricks with the assistance of ChatPGT
- Understanding Large Language Models (LLMs)
- What is Prompt Engineering? Unlock the value of LLMs
- LLM Pipelines / Graph Data Science Pipelines / Data Science Pipeline Steps
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: