CONTACT US
What is a Graph Database? Complete Overview
As a database developer or analyst you may have heard of “graph databases” but perhaps not know exactly what they are or how to use them. In this article we’ll share what is a graph database along with some use cases, as well as how graph databases can drive value.
What is a Graph Database?
Simply put, a graph database is a database that is designed so that connections between the data are considered as important as the data itself. It also stores the data flexibly in such a way that it is not restricted to a rigid existing model. The data is maintained in the database much like you would see it drawn on a whiteboard- showing clearly each entity and how it is “related” or connected to other entities.
Like any other database system, graph databases (such as Neo4j) facilitate the efficient storage and retrieval of data to support a variety of uses. Much like the historically popular RDBMS database, graph databases also provide a way to consistently and systematically organize data to support the questions, domain-specific knowledge, and unique applications that are at the core of any organization. However, it is how that data is stored and retrieved which fundamentally differentiate graph databases from other traditional SQL-based RDBMS systems. And it is by examining those differences which can shed light on what exactly distinguishes graph databases from the many other data storage options that are in use today.
Why Graph Databases?
The most fundamental aspect of a graph database to understand is the data structure which it uses to store data, called a graph.

Comprised of a set of nodes connected by relationships or edges, graphs have been a fundamental structure in computer science for decades and in math for centuries due to their ability to more optimally describe the complexity of naturally occurring connections within the world. Since graphs store data much like the human brain- by connecting concepts together via the relationships between them- they offer a more intuitive medium for storing, analyzing and understanding data through the lense of those connections. It is no surprise that these valuable natural connections are everywhere in our data. By taking advantage of this reality with a native data store that accommodates this inherent connectedness in our data, graph databases are able to store our data, at scale, with a specific focus on preserving the uniquely valuable and intrinsically interconnected information and patterns found within. This simple example below provides more visual insight into that value.
How is a Graph Database Different?
Consider the following traditional tabular dataset:
| Name | Job | Address |
| Sonya | Pilot | 101 N Main St |
| Parker | Food Service | 101 N Main St |
| Alex | Pilot | 455 West Ave |
For the purposes of simple record keeping and lookups, this rows-and-columns tabular structure works quite well (as used by classic RDBMS data stores such as Microsoft SQL Server and MySQL etc). If we were to ask a question such as “Where does Sonya live?” then arriving at the answer is straightforward. We simply do a lookup on our Sonya record, examine the “Address” column, and we have our answer. However, if we were to ask a more inherently interconnected question like “Who also lives at Sonya’s address?” we’re presented with a scaling challenge when using more traditional tabular formats to attempt to answer these kinds of questions.
To answer this from a tabular data store, we would first have to do a lookup on our Sonya record much like before, capture their address, and then conduct yet another lookup based on this address in order to get an answer. And while this may seem like a trivial addition in the context of a simple example such as this, the complexity and computing resources required at enterprise scale can quickly make asking these kinds of critical interconnected questions untenable- particular as we add more connections and ask more complex questions.
Graph Database Example
Let’s take a look at this from the perspective of a graph. To structure this data as a graph, we simply extract all of the distinct entities in the data and treat them as nodes:
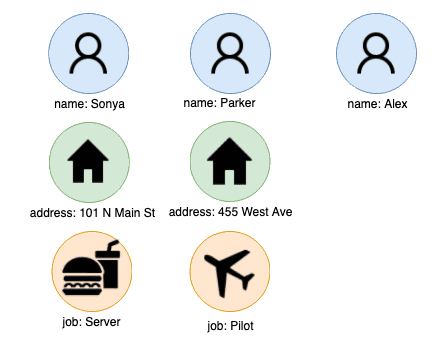
Sometimes, this is as simple as collecting the unique values from each column. However, for less structured data such as raw address strings, emails, or company names, this process could require some extra data prep through an entity resolution process, which is often one of the first things users go through when adopting graphs for the first time. In the same way, using modern Natural Language Processing (NLP) techniques, graph databases are even a uniquely scalable fit for driving the potential value from the massive amount of typically un-leveraged unstructured data in the enterprise (e.g. customer reviews, social media text, product documentation, listing descriptions, internal knowledge bases, external legislation etc), which is also highly connected in nature.
After this step of extracting the unique entities, we then create the relationships or edges between any nodes which share a connection to that record, by specifying the type of relationship between the nodes. This allows us to not just store the reality that two nodes are related, but also store how two nodes are related which will further capture the connected nature of the data and enable us to now perform difficult if not previously impossible operations by utilizing the information stored in those relationships. Doing so gives us the following graph:

Now recall our question from before “Who also lives at Sonya’s address?” With our data now structured and stored as a graph, this question is very straightforward. We start by locating our record in question by looking up the node that represents Sonya:

After locating our node in question, finding their address record is as simple as a quick traversal through the HAS_ADDRESS relationship/syntax:

Now to reach the final answer to our question, we need only to follow all other HAS_ADDRESS relationships which are connected to the address node. Doing so quickly locates all adjacent records without the need for additional lookups, reducing both the time and complexity of our query.

By utilizing the naturally interconnected nature of graphs as a data structure, we are able to transition from asking our questions with a series of expensive and often complex SQL lookups across many rows and columns of rigidly stored data, to a simple series of traversals using some flavor of a Graph Query Language (e.g. Cypher, Gremlin etc) across data who’s adjacency serves as a high speed avenue to arrive at an answers to our complex connected questions. And while graphs and graph theory has been used by mathematicians and computer scientists for years to solve a number of interconnected questions such as this, it is only in the last decade where we have seen these powerful data structures used as the backbone of purpose-built databases that now power scalable storage and retrieval of interconnected data within businesses.
Graphs are Here to Stay
With Gartner accurately predicting that the graph database market would grow at 100% annually, and that graphs are forming the foundation of modern data analytics capabilities to such a degree that by 2021, graph tech will be used in as much as 80% of data and analytics innovations, the meteoric surge in the adoption of graph databases and graph analytics will only accelerate in coming years as organizations seek to leverage their data more effectively and for competitive differentiation in ways that have not been previously possible.
In 2019, Google made the statement that after doing data science in various other ways, they have concluded that to be most successful, much of data science/machine learning going forward will rely on ‘models of networks’ (e.g. graph databases):
“Human cognition makes the strong assumption that the world is composed of objects and relations… and because graph networks [graph databases] make a similar assumption, their behavior tends to be more interpretable.”
Whether organizations are pursuing much more effective and scalable e-commerce recommendation engines, market basket analysis, supply chain management, IOT, MDM, fraud detection to name a few examples, with the top companies in technology leading the charge, graph databases are here to stay as an integral part of our business technology landscape.
Read Related Graph Articles
- What is Graph Data Science?
- What is Neo4j Graph Data Science?
- What are Graph Algorithms?
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: