CONTACT US
Building Recommendation Engines (3-Step Guide)

While the name “recommendation engine” might seem to imply it all, there is so much potential in this technology approach that it’s worth digging deeper. As the importance of engaging customers and other stakeholders grows – as the reality of remote engagement itself continues to grow – building recommendation engines and employing their many different uses are rapidly becoming a fundamental capability for organizations.
Possibly the most common recommendation engine experience we all have is when streaming video services suggest new content for us to watch. Not surprisingly, those companies focus on building recommendation engines to find and suggest this new content to us, based on all our previously watched content. While streaming content recommendations, and perhaps even product recommendations from our favorite e-commerce websites are easy to imagine utilizing this technology, we should ask how else recommendation engines can benefit organizations.
There are any number of additional use cases, but many question arise in considering them: Is the ROI sufficient to justify the time and money to implement them? And how would one get started, given that the best approaches and technologies are relatively new, and true expertise hard to find? Many organizations believe that recommendation engines must be so complex, timely, and costly, and this can often cause them to shy away from exploring the significant potential value.
In this article we demystify recommendation engines, covering what they are, what organizations can gain from them, and even provide an example approach to start building one. The article itself is geared towards organizations that are newer to graph databases and to graph data science, or that may not have the internal technical resources to explore this on their own.
What’s the Value of Building Recommendation Engines?
What is a recommendation engine, and what’s the value of building recommendation engines? They allow us to tap into and traverse the breadth of valuable data across an organization- whether it be structured and/or unstructured data- in order to take people, content, products (as a few examples, but really any other entities in the data) and to connect them in ways that are only possible programmatically, and only possible at scale with graph databases (e.g. Neo4j) and graph data science technology. By connecting potentially valuable “entities” in your data to other potentially impacted/interested entities, there is an opportunity to create net-new value through the those new connections.
Obvious examples as mentioned above include e-commerce recommendations – where recommending the right product to the right person at the right time in order to create enough value in the buyer’s mind to purchase and/or add on to a purchase can be the difference in them staying or changing to a new vendor; or with streaming services, mining the content in ways that surface new recommended content to keeps viewers from jumping to the many other streaming options out there. It starts to become very clear that the effectiveness of the recommendation technology to produce only the most relevant recommendations is core to producing value.
Beyond the most common use cases mentioned above, building recommendation engines can help in so many other ways- really only constrained by the needs and imagination of each organization. Some examples of other valuable use cases include:
-
Looking across medical research, patient profiles, clinical trials and more to help doctors recommend optimal treatment plans
-
Using customer purchase history data to recommend even quantity of products to purchase,
-
Leveraging customer user profiles and internal store data to recommend new more convenient store locations,
-
Using social media data to recommend staffing and capacity needs for upcoming events,
-
Using event and employee data to recommend relevant events/programs to employees,
-
Using internal structured and unstructured data to surface (recommend) an organization’s top X employees to focus on for retention efforts,
-
Using internal and external (e.g. legislation, news) structured and unstructured data to recommend the top X unknowns or possible risk areas for a larger company to consider,
-
Finding and recommending de-duplication opportunities across compliance requirements.
The list really could be endless based on the unique internal and external needs and/or opportunity areas of an organization. Many are calling data “the new gold” for businesses. Those that can imagine beyond the traditional recommendation use cases will set themselves up to compete much more effectively by mining their data for value in this unique way.
Guide for Building Recommendation Engines
To begin building recommendation engines, you need interconnected data in a graph database such as Neo4j. Though not required, storing your data in this way enables you to traverse your data much more efficiently particularly at scale, enabling lightning fast insights by avoiding the expensive joins that would be required in a relational database. For more information on the benefits of a graph database, read this post on what is a graph database or learn more about: What is a knowledge graph?
When building recommendation engines for the first time, one approach is to follow a simple three-step question approach that breaks down the process, using the collaborative filtering approach mentioned above. Once you have your interconnected data loaded into a graph database, such as customer purchase history data, it is important to start this approach out with with a single user.
Starting with a single user enables you to filter the data so you can easily see the results without extra noise. Formulate a question that can be answered with one relationship, or one hop, from your starting user. The first question could be “what products has this user purchased in the last 6 months?”. With that question and a single user, query the database and pull all answers to that question, as shown in the image below.
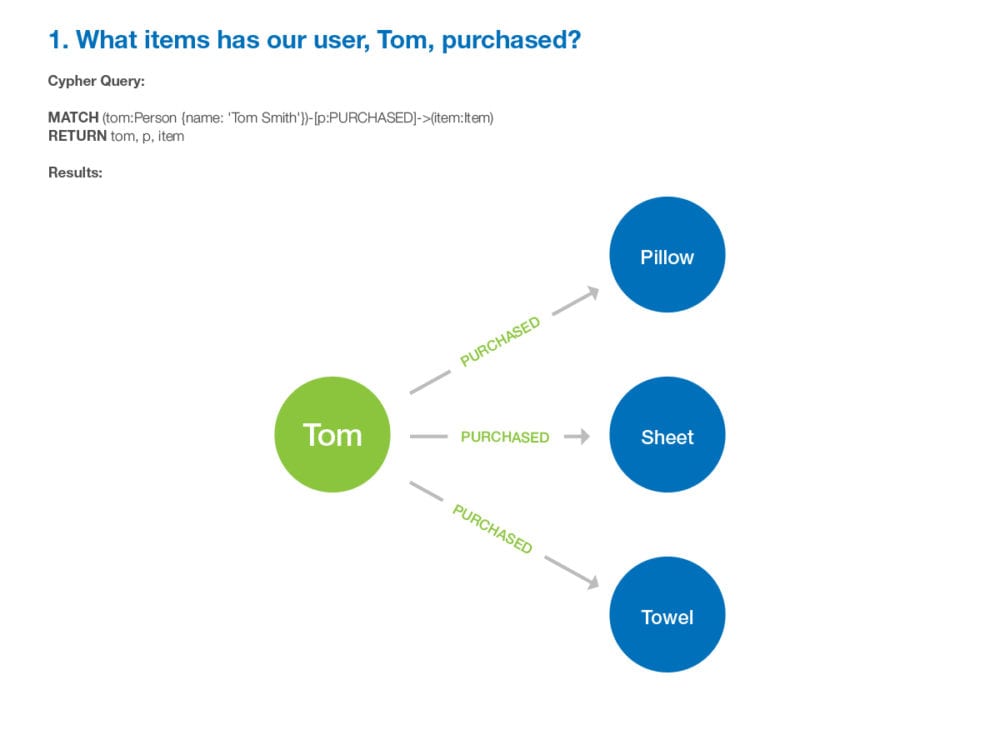
Next, build on the query by asking a question that can be answered in two relationships, or two hops, from your starting user. The question might be, “what users have also purchased the products that our starting user purchased?”. The results give you a number of users who are connected to your starting user through a similar product that they purchased.

Lastly, query the database to ask a question that is 3 relationships, or hops, away from your starting user. In our example, the question is “what other products have our related users bought, that our starting user has not bought?”.
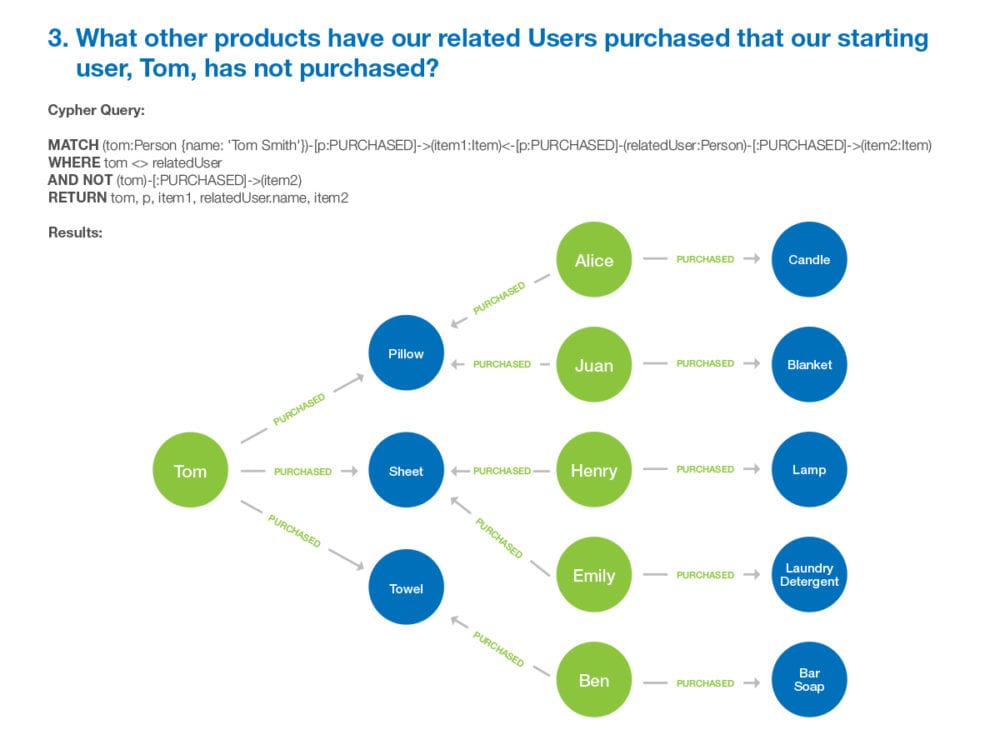
With that final result, in 3 simple questions, you just created a list of potential products as shown below, that you might recommend to your starting user, in essence creating a simple recommendation engine. Clearly, there is much more to ensuring that those products will fit the starting user, but this is a way to show the backbone of the process where the relevance is based on the fact that people who buy one thing often buy other similar products.
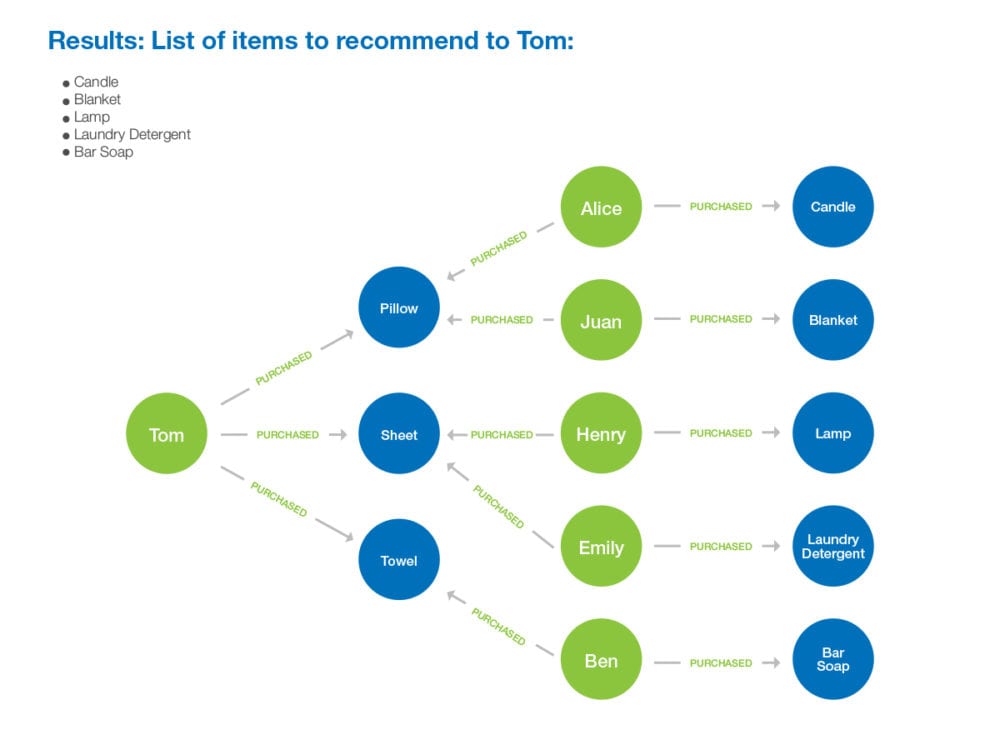
This 3 -tep question process can be applied to any interconnected data, driving recommendations and insights from your data in minutes. After going through this kind of process, you can continue to build on it, adding more context through questions and through more data, increasing both your question complexity and the possible insights you can gain.
Barriers in Building Recommendation Engines
Outlined above is a simple example of leveraging customer behavior data in order to understand purchasing patterns for the purpose of recommending products to customers. It is evident though that the most popular products will always be the most recommended, if we use only this collaborative filtering approach. While it can be effective, some of the downsides of this approach are:
- It is not well suited to account for new product launches (e.g. no one or very few people have purchased them),
- If you are trying to give your customers a wider variety of recommended products that may be a fit, but may not connected through similar customers, but instead perhaps through other means.
Graphs can also solve this problem by matching products to customers along any other dimension (e.g. weather data for a customer’s particular location could drive very tailored product recommendations), even using unstructured data (with Natural Language Processing or NLP) such as reviews, user guides, descriptions and more to find that relevance. Using movies as another example, recommendations could be made based on the cast, genre, production company or even filming location and a whole host of other dimensions, leveraging a user’s rating data to find the connectedness across those dimensions.
As a foundation for your recommendation engine, graph databases have the advantage of being a uniquely efficient data store, in that the model itself is optimized for sub-second traversal across any number of relationships and dimensions, whereas traditional relational databases often fail to scale with any amount of complexity in these kinds of use cases. Graph even has the capability to weight relationships and entities (nodes) enabling much more nuanced querying based on numeric levels of certain characteristics (attributes). For example, a particular movie (represented as a node in the database) might be simultaneously 50% horror, 20% drama, and 10% comedy, and can carry those attributes as part of the node.
Calculating a user’s preferences based on their past viewing history, its then possible to create a graph query to find movies that combine all of the many possible attribute scores, based on a combination of dimensions that matter to the user, enabling much more nuanced and even unexpected but uniquely helpful movie recommendations. By leveraging the depth of dimensions available in the data, more and more possibilities emerge, that are increasingly more relevant to the user. This is the kind of precision in finding relevance that matters in today’s context in order to thrive in an increasingly competitive environment.
For an even deeper dive on recommendation engines, you can read the post
“What is a recommendation engine?”.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: