CONTACT US
What Is a Recommendation Engine? Knowledge Graphs and the Hume platform

Our previous blog article highlighted the critical advantages of a knowledge graph and answered the question: What is a knowledge graph? Being flexible by nature, they easily relate connected data across the enterprise, whether structured or unstructured, flat or hierarchical, all can be linked together in the graph.
In this article, we’ll answer the question: What is a recommendation engine? and explore graph recommendation engines. We’re going to focus on the most fundamental use case for knowledge graph recommendation engines. Because knowledge graphs hold linked data together, they provide some interesting opportunities to layer in additional context to the recommender algorithm.
If the graph recommendation engine leverages unstructured freeform descriptions of products, services, media, or events through the knowledge graph, it will be able to return a richer and more diverse result. Having this added diversity is essential for customer experience as it will feel less rigid and formulaic, creating a feel of personalization. The slideshow below illustrates how a product lifecycle graph evolves as more contextual information is added.

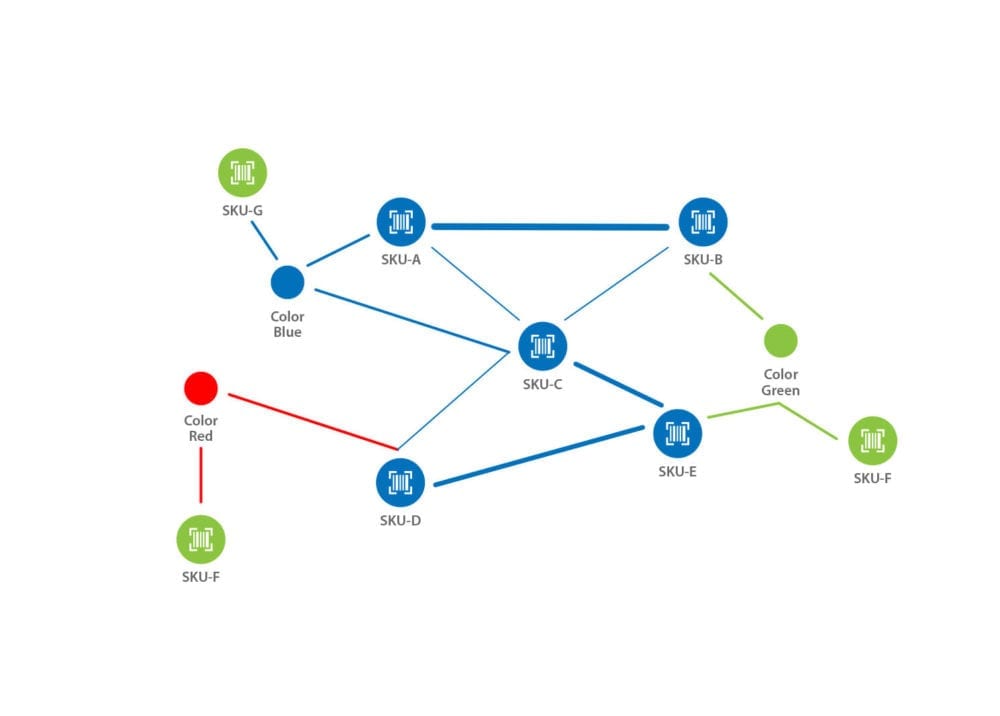

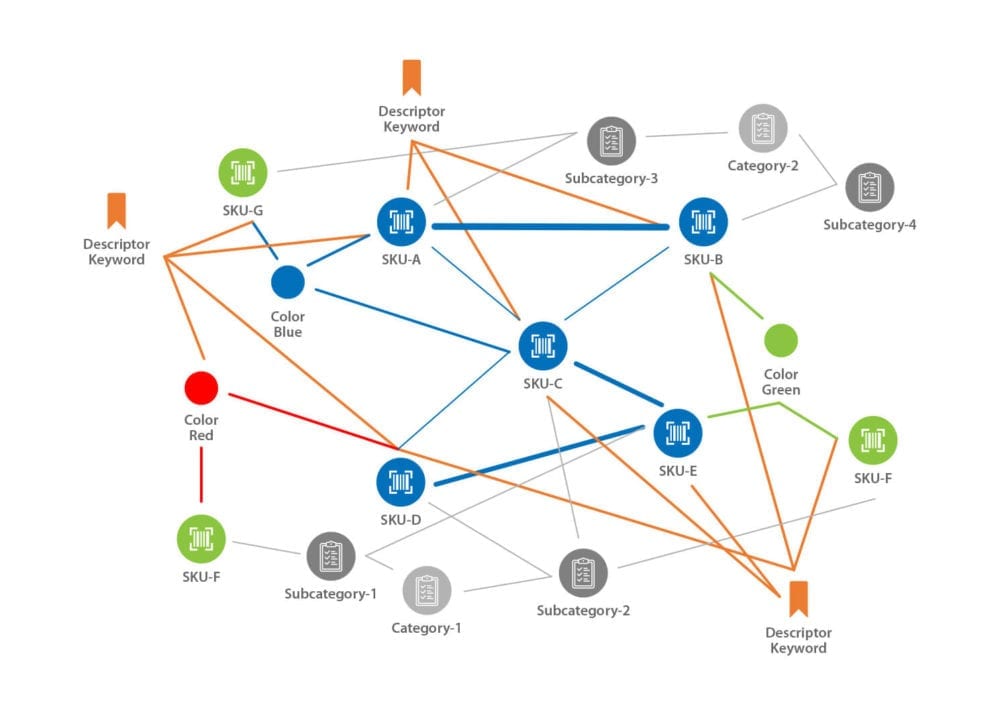
What Is a Recommendation Engine?
Generally, recommendation engines are a class of algorithms and models used to suggest ‘things’ to users. These algorithms use user behavior patterns to find and serve the most likely item(s) of interest to the user. The earliest and most widely used form of a recommendation engine is the “people also bought” algorithm, built using a market basket analysis approach.
Nowadays, the complexity of recommendation engines can vary widely, as organizations take different approaches to construct and deploy them. For example, some recommendation engines are built to learn more about a user over time, so as to continuously improve recommendations. Others might use “collaborative filtering”, which uses the abstracted behavior patterns and preferences of the many to find the most relevant products to serve to particular users.
Each organization must choose the approach that works best for them, given constraints around the availability of data, industry, or user type as well as desired functionality. Implementing a recommendation engine does not have to be a single monolithic, time-consuming project, but instead, it can be broken down into phases, starting with a very specific use case and corresponding recommender systems approach, evolving it over time.
This is critical for organizations that to date may have considered these kinds of technologies out of reach. Starting simple can drive measurable value early, while also surfacing knowledge about the most effective approaches for each organizations’ unique context and goals.
How Are Recommendation Engines Built?
In general, recommendation engines are built probabilistically using “collaborative” methods for filtering. Perhaps the most widely known method of building recommendation engines is the use of market basket analysis. Simply, the algorithm tracks the products that are most likely to be purchased together in the same transaction or across multiple transactions to estimate lift.
When you buy Product X for example, Product A, which happens to have the highest lift with Product X will be recommended. Another collaborative method is the “people who bought also bought” approach. In this case, the algorithm would look for other customers who also bought Product X and see which product was most likely to be bought with Product X by this subset of customers.
While easily operationalized, collaborative, history-based approaches have some clear drawbacks. For one, they all suffer from the “cold start” problem. Newly launched products would never be recommended because they have not been given the opportunity to be purchased with other products.
A second problem is that the most popular products will eclipse the rest of the assortment and over time, every customer will be receiving the same set of recommendations. Worse still, the customer might end up seeing recommendations for products that they have already purchased, creating a clunky and uninspiring experience. Think of basket-based recommendations as the meat and potatoes of recommendations, extremely bland without a little spice.
Context Matters
While purchasing patterns are a good entry point into understanding purchasing behavior and the most relevant items, it lacks a key ingredient: context. Human decision-making is fundamentally contextual in nature. The decision to purchase any given product or service usually involves a nuanced and “embedded” process, balancing cost, brand, category, expected return, and a whole host of other factors.
Even something as simple as preferring products or brands with an ocean theme could be the tipping point that makes a person say “Yes”. Recommendation engines will need to be able to tap into the contextual information surrounding the products to be able to deliver relevant products to the customer.
Conventional wisdom would create product data using rows and columns to build contextual data such as product hierarchies and other pieces of information such as color, material, etc. Building product data for context is no easy feat, especially where the data schema is concerned. If the assortment contains products that are nuanced and complex, building a table or even storing the product as a JSON can become fairly complicated.
Say we have a shirt that could have sleeves of a different color, and on those sleeves are additional trim that could be the same or different from the body. On the body there might be a logo that is placed on multiple different backgrounds and the logo itself allows for different foreground and background combinations. Colors have to be assigned to a color family and if additional marketing embellishments are added to the products (example “vanilla” beige) would require additional tables or levels of nesting.
Trying to triangulate “similar” products will be extremely difficult, with many self-joins to align products to one another. Complicating matters, these joins have to bebinary (yes / no) matches, no fuzziness allowed.
Knowledge Graph Recommendation Engines
Clearly, context is the secret sauce that gives life to recommendations. This is where the ability to instantaneously and simultaneously evaluate relevance on a variety of different dimensions is critical, exactly why a knowledge graph is needed. A primary benefit of deploying a graph solution is that it readily handles many-to-many relationships, where relationships change as a function of context. Another plus of the knowledge graph is the ability to store additional data on the relationships, giving us added analytical capability for weighted relationships. For example, we might place more importance on product category in certain situations, while in others, color might have to be prioritized.
It is important to note that these knowledge graphs do not need to store transactional data, where each and every purchase of a given item is left in the database. The goal of having a knowledge graph is to create contextual, connected data. This means that co-purchasing patterns for products should be stored with support, confidence, and lift values as properties of the relationship between them. These values can be refreshed on short or long time frames, depending on how responsive to purchasing trends the recommendation engine needs to be. Because relationships in the knowledge graph are fuzzy and weighted, the priority of co-purchasing patterns can be reduced, for example, during new product launches, where similarity along contextual dimensions such as color, style, etc. should be assigned the highest importance. At this point in its development, the knowledge graph will already a flexible system, adaptable to a variety of different situations and needs, but there is still more that can be done.
Beyond Structured Data — Leveraging the Unstructured
Certainly, structured product context data adds a level of additional richness to any recommendation engine. Yet, building and managing structured product context data is often both costly and onerous. Creating controlled vocabularies and developing the appropriate fields to describe a product is an extremely difficult process as no one can truly be able to predict every possible dimension required to describe future products. And, so much of the creative copy for product descriptions ends up being left by the wayside where recommendation engines are concerned.
This is where unstructured data can play a critical role. Product descriptions are the best example of unstructured data that can be mined to expand the capabilities of any recommendation engine. There is a wealth of contextual information that can be mined out of these unstructured data sources. Think about all that word-smithing that had to be done to get the descriptions just right to begin with. The same is true for all the words and text contained in all those user reviews that just cost too much to be reviewed by humans, and more importantly, filtered for fake reviews.
Integrating Creative with Science — Introducing Hume
As a product assortment grows, keeping track of how each and every piece of creative copy has been written becomes exponentially more difficult. Layer marketing, advertising, and promotions on top, maintaining consistency in the messaging as well as tracking trends is something everyone would like to do but usually cannot do well, if at all. Not to mention, there are new products being launched that we would like to recommend, where there is no sales history.
This is where having a software platform that can be used by both the knowledge graph builders and the creative copywriters to collaborate and simultaneously evaluate copy and visualize the collective patterns of how products relate to one another tp drive that content in an optimal direction.
Enter Hume, a graph-based software platform (leveraging Neo4j) that enables knowledge graphs to be engineered with a point-and-click interface. Complete with tools to ingest data and parse it from freeform text, JSON, or tables, Hume will transform that data and ingest it into a knowledge graph.
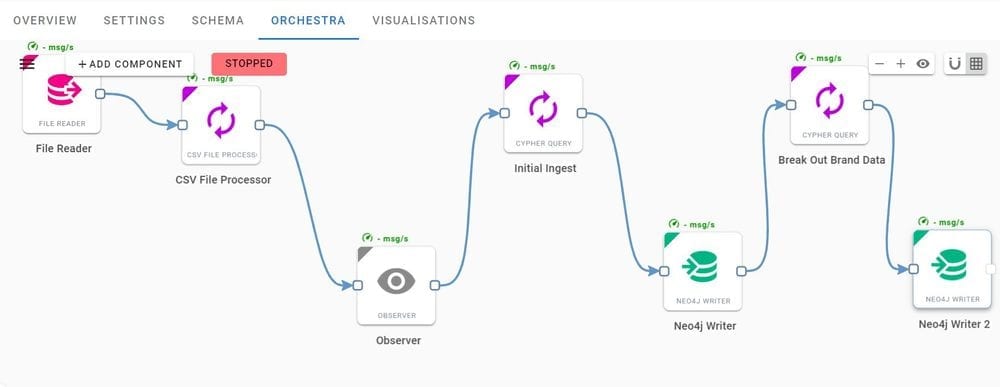
All you have to do is design your knowledge graph and Hume will do the rest, transforming and loading your data into the graph. With fully built in visualization capabilities, you can see search for products and see different segments of your product network. The Hume visualization enables us to see what products tend to get sold together or have common attributes with a click-and-drag interface. This screenshot from Hume’s Orchestra function shows easily data can be put through a process to loaded into a knowledge graph.
While much free text can be parsed through natural language processing (NLP) models that are available in Hume, oftentimes we need to create custom models for a specific domain or subject area. Hume enables you to manually annotate text to and link concepts create models that may be specific to your domain, as shown below. With these models in place, the system can then recognize important words and topics from your domain as data is being ingested, driving a more complete and valuable knowledge graph for your organization.

Importantly, Hume enables custom “actions” to be created, parameterized, and tested. These are algorithms that can be written and tested in the graph. Imagine having something like an SEO engine where you can test the impact of different product launches and where these new products might fit into the overall product network.
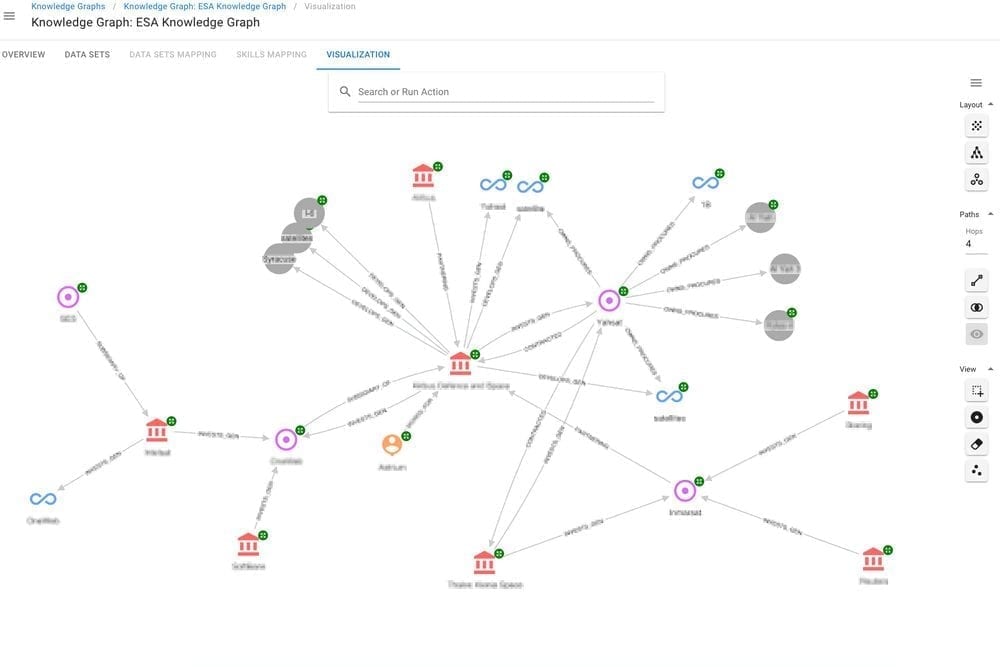
These custom actions also let you re-weight and prioritize different attributes or relationships in order to try bring subject matter expertise and test different “what if” scenarios directly in Hume. Essentially, this is an opportunity to take a peek into the future of your products, depending on how you link them together. Here is a screenshot from Hume’s visualization layer where you can use custom actions to detect insights from your knowledge graph to find points of convergence.
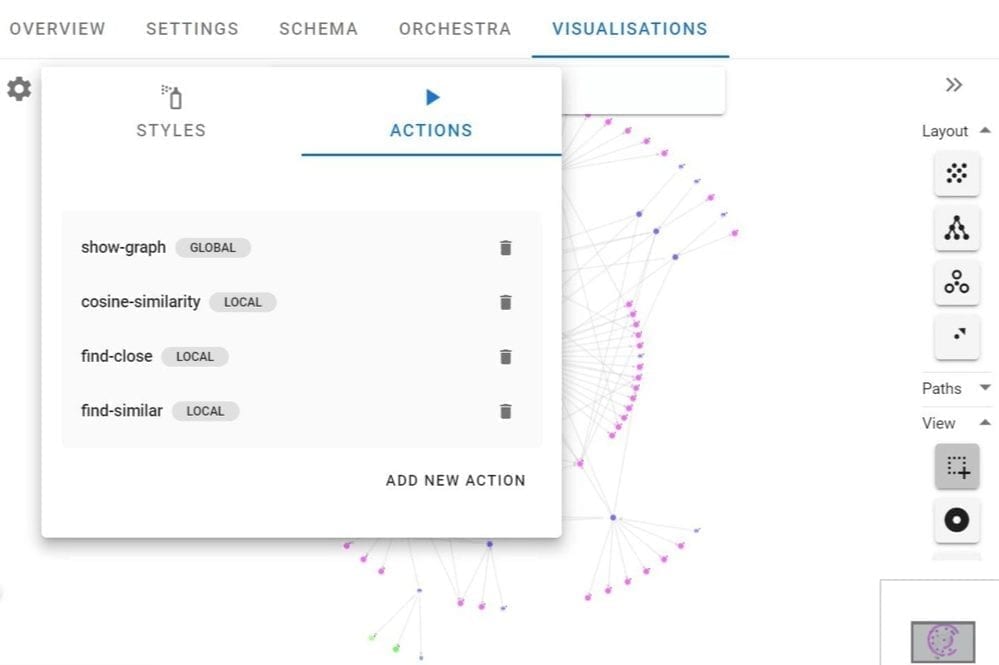
Lastly, whether you’re navigating and analyzing the graph, looking at schema, creating alternate views, and more, the Hume visualization layer is the way end users and developers alike can interact with the knowledge graph.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: