CONTACT US
Neo4j Graph Data Science: Powerful Innovation and Interconnected Insights
By: Sean Robinson (Director of Data Science), Golven Leroy (Data Scientist, Guest Contributor)
In this article, we’ll take a look at the Neo4j Graph Data Science Library by examining its capabilities, how it can be used with a Neo4j database, and how you can get started with the Neo4j Graph Data Science Library yourself.
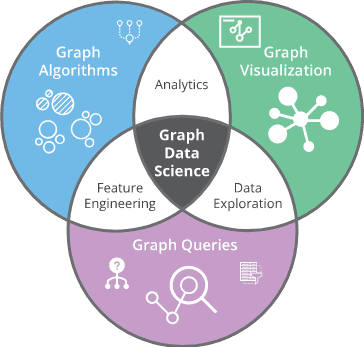
What is Neo4j Graph Data Science?
Data Science in general differs from traditional analytics methods in that it incorporates advanced tools and techniques like machine learning (ML) / artificial intelligence (AI), and natural language processing (NLP) to make the most insightful, data-driven decisions and predictions possible. While traditional methods using graphs rely heavily on advanced statistics and graph-theory-related mathematics algorithms in order to summarize and analyze data, Neo4j Graph Data Science Library goes far beyond these disciplines to bring in extra-disciplinary knowledge and capabilities to its graph data science offering. Some examples include:
- Graph ML capabilities to drive more accurate predictions, to a level that is not often feasible using purely statistical approaches.
- Out-of-the-box ML pipelines for common use cases such as anomaly and fraud detection, recommendation engines, route optimization, and more.
- Project-to-production capabilities. Moving AI /ML projects from the development stage to production is difficult and requires significant and ongoing “tinkering” from qualified data scientists to accomplish that. The Neo4j graph data science library is built for deploying production-ready projects by leveraging experience, best business practices, and data science knowledge to provide many workflows to help expedite your business value.
The 4 Reasons Businesses Need Neo4j Graph Data Science / Graph Database for Critical New Insights
Graph data science (GDS) is increasingly demonstrating its place as part of the next generation of tools for advanced analytics for businesses and organizations as they continue seeking to gain a competitive advantage in a diverse marketplace.
Reason 1: Massive Data Scale Requires It
Many organizations have large and ever-increasing volumes of complex data for which traditional relational databases are not well-suited to handle. In contrast, graph data science on graph databases like Neo4j provide a much more suitable means to store and analyze this volume of data in an interconnected way that highlights the connectedness of the data, which is becoming particularly important for the increasingly advanced questions business leaders are asking of their data
Reason 2: Data Complexity Requires It
Complex data relationships in traditional databases require complex queries that can be slow and inefficient as they attempt to traverse disconnected datasets through joins and foreign keys. In contrast, graph databases are designed to optimize these connections thought relationships, making data analysis, including graph data science, faster and more efficient. This is especially useful for businesses and organizations that need to analyze large amounts of data in real-time to make informed decisions.
Reason 3: Relationship Accuracy Requires It
Data science conducted on a graph database (see more at What is a graph database) provides a more accurate real-world representation of complex data relationships where the critical insights are centered around how entities may be connected. Traditional relational databases are not well-equipped to handle this kind of interconnected data at scale. As a result of the frequently stilted modeling required, they can produce inaccurate results when attempting to analyze such data, with extensive queries requiring inordinate amounts of time to process. In contrast, graph databases are specifically designed to quickly manage complex, interconnected data relationships, with much less code required, making them more accurate and usable for data science and decision-making.
Reason 4: Advanced Insights Require It
Finally, because of the uniqueness of the surrounding technologies used to query and analyze the data, graph databases enable organizations to gain insights into their data that would be difficult if not impossible to obtain with traditional relational databases, whether using graph data science or not.
This can lead to optimized businesses and better decision-making driving competitive advantage in increasingly competitive landscapes. By using graph databases, organizations can surface incredibly valuable patterns and relationships within their data that were previously hidden in their vast amounts of data, enabling organizations to make more informed, better decisions.
Why Choose Neo4j Graph Data Science?
Neo4j in general offers a host of unique capabilities that make it a superior option for advanced data analysis and data science. Here are some of the most important examples:
- Graph algorithms: The Neo4j graph data science library includes a comprehensive set of graph algorithms that can be used to identify patterns, relationships, and anomalies in data. These algorithms are optimized for use with graph data, making them more accurate and efficient than traditional data analysis methods.
- Graph Machine Learning: The Neo4j Graph Data Science library offers a wide range of benefits when it comes to graph machine learning. One of the key advantages is its ability to leverage the inherent structure and relationships within graph data. By incorporating graph-based features and algorithms into the machine learning process, the library enables data scientists to extract richer insights and achieve more accurate predictions.
- Python Client for Data Scientists: The Neo4j Graph Data Science Python client offers myriad benefits for data scientists seeking to harness the power of graph data analysis. Firstly, this client provides a seamless and intuitive interface, enabling data scientists to effortlessly interact with Neo4j’s graph database using Python. By leveraging the client’s comprehensive set of functions and algorithms specifically designed for graph data science, data scientists gain access to an extensive toolkit for performing complex graph analytics.
- Machine Learning Pipelines: One of the key advantages provided by the Graph Data Science Library is its ability to seamlessly integrate graph analytics with machine learning workflows. The library provides a comprehensive set of tools and functionalities that enable data scientists to incorporate graph-based features and algorithms into their machine learning pipelines, resulting in more powerful and insightful models.
- Native Graph Processing: Neo4j is a native graph database, which means it is optimized for processing and analyzing graph data. This allows for faster query performance and more efficient data processing. Read more on Neo4j performance and architecture.
Where Should You Start?
For installation of the Graph Data Science Library, we recommend following the Neo4j documentation here. Once GDS is set up, use these tips for best results:
- Tune the graph database configuration: Neo4j provides many configuration settings that can be tuned to optimize query performance and data processing. Adjusting these settings can help to speed up query response times and improve overall performance, which can make a big difference when running certain algorithms.
- Use appropriate graph algorithms: Neo4j provides a wide range of graph algorithms for various types of analysis, which is amazing, but it can be overwhelming at first. We recommend experimenting and researching which algorithm is most appropriate for your analysis goals. Different algorithms might have different rates of success! Once algorithm will most certainly not answer all of your data questions, and all of your analysis goals might not require full-blown GDS.
- Use Neo4j’s GraphAcadmy: Ultimately, if you want to have the best chances with Neo4j GDS, we recommend following the learning path for the Neo4j Graph Data Science Certification. It will take you through proper installation, cataloging, administration, cypher on GDS graph and overall Graph management.
Conclusion
Neo4j’s graph database has made it possible to extract crucial insights from complex data for several years. However, with the introduction of the Neo4j Graph Data Science Library, it has finally bridged the gap between data science and traditional methods of graph analytics. This has become increasingly important for businesses and organizations as they seek to gain a competitive advantage by analyzing large volumes of complex data.
With its superior features such as native graph processing, graph algorithms, data visualization, data import and export capabilities, scalability, and flexible data model, the Neo4j Graph Data Science Library is a valuable tool for data science teams looking to take their analytics to the next level.
Related Articles
- AI in Drug Discovery – Harnessing the Power of LLMs
- AI consulting guidebook
- What is ChatGPT? A Complete Explanation
- Domo custom apps using Domo DDX Bricks with the assistance of ChatPGT
- Resolution for various ChatGPT errors, including ChatGPT Internal Server Error
- Understanding Large Language Models (LLMs)
- What are Graph Algorithms?
- Conductance Graph Community Detection: Python Examples
- What is Neo4j Graph Data Science?
- What is ChatGPT? A Complete Explanation
- ChatGPT for Analytics: Getting Access & 6 Valuable Use Cases
- What is Prompt Engineering? Unlock the value of LLMs
- LLM Pipelines / Graph Data Science Pipelines / Data Science Pipeline Steps
- Using a Named Entity Recognition LLM in a Biomechanics Use Case
- What is Databricks? For data warehousing, data engineering, and data science
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: