CONTACT US
The Exceptional Value of Graph Embeddings
The world of graph embeddings is valuable but complex. Find out how to generate and then apply these graph embeddings in a variety of different application contexts to uniquely harness the interconnected information they contain.
Understanding Graph Embeddings
Before we can dive into the power of graph embeddings, it is critical to understand the concept of what graph embeddings are and how they are generated.
Much like word embeddings or document embeddings which have exploded in popularity in the natural language processing space, graph embedding models allow us to capture the topological structure of a given graph to generate vector representations of the graph’s contents. In practical terms, this means being able to generate node-embedded vectors, for each node in the graph and then use the embedded vectors to solve for a variety of use cases.
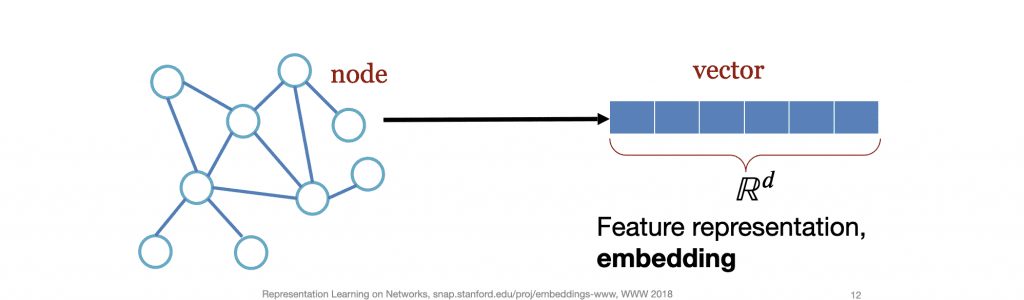
The Task of Embedding in a Graph
To generate these embedding vectors, we must first define foundational two concepts that can also be represented as functions:
- What defines similarity between two nodes?
- How do we encode the nodes of a graph using this similarity measure?
Mathematically, we can define these questions as follows:
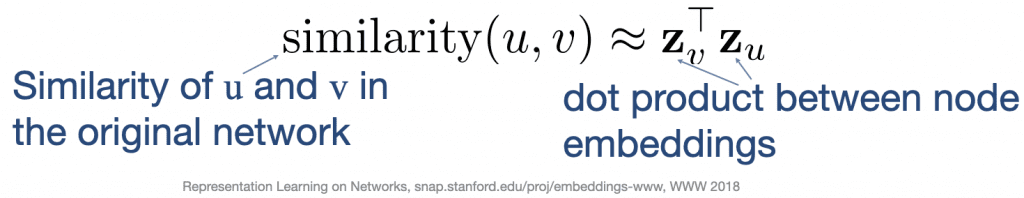
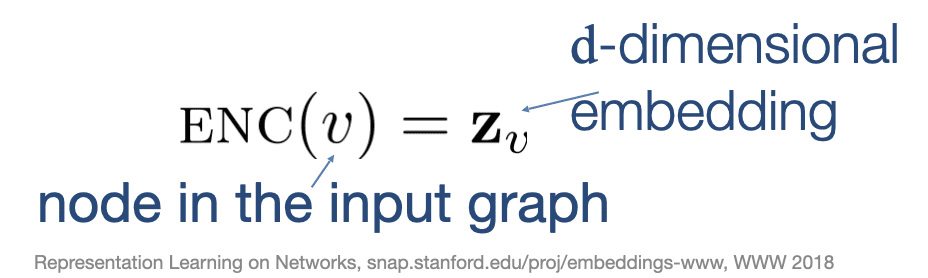
Given these definitions, our encoding function should generate d-dimensional vectors for each node in our graph and the distance between these vectors in our embedding space should be reflective of our similarity definition. Therefore, two nodes which are dissimilar according to our similarity definition will be distant from one another in the embedding space and likewise, two nodes which are similar according to our similarity definition will be close together in the same embedding space.
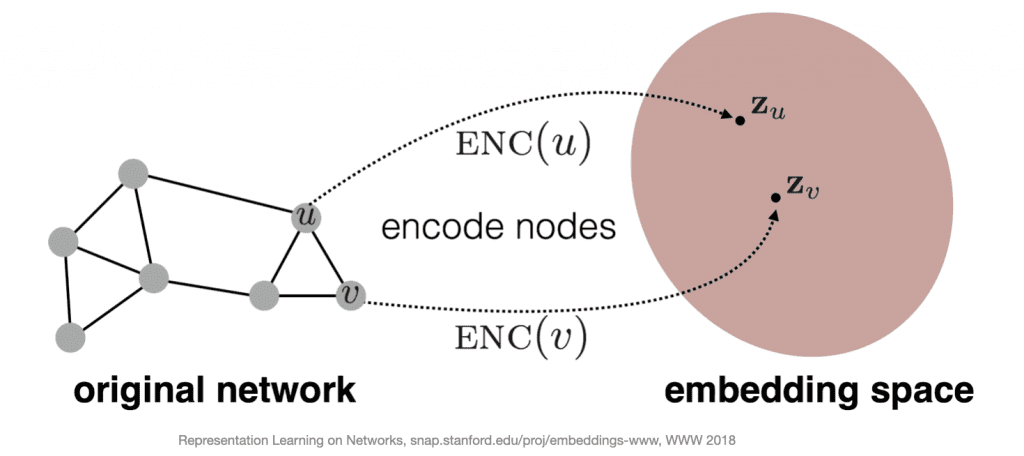
Similarity and Encoding Strategies
The main distinction between various families of graph embedding models is in how they define these two functions. Here we will examine a few examples of how various types of models approach these problems in different ways.
Adjacency-based Approaches
One of the simplest and most intuitive approaches to defining similarity is by looking at the adjacency between two nodes v and u.
- Similarity: Two nodes are adjacent to one another within the structure of the graph
- Encoding: Find the embedding matrix Z that minimizes the loss function L
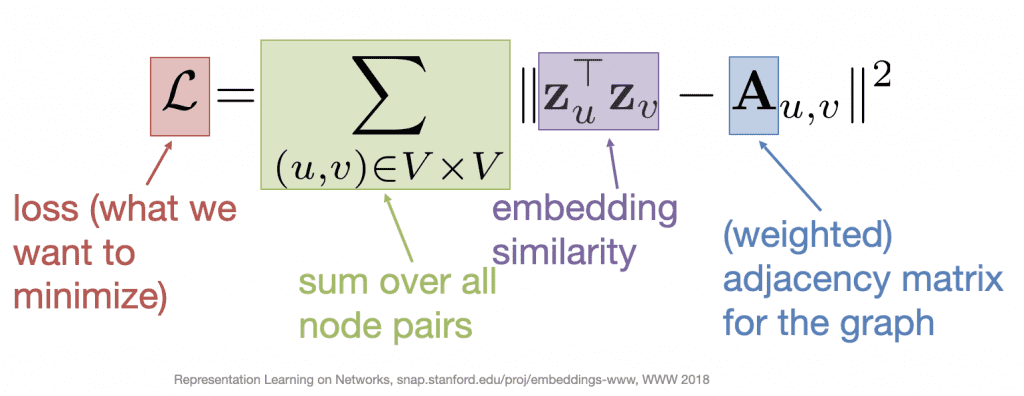
Here we are using the entries for nodes u, v in the weighted adjacency matrix of our graph A to encode the distance between our embedding vectors Zu, Zv.
While this is an intuitive approach, it quickly reveals its shortcomings when examining how this method fails to capture the similarity between distant nodes.

To address this shortcoming, we must consider methods that take into account nodes that are not directly linked to a given node v.
Random Walk-based Approaches
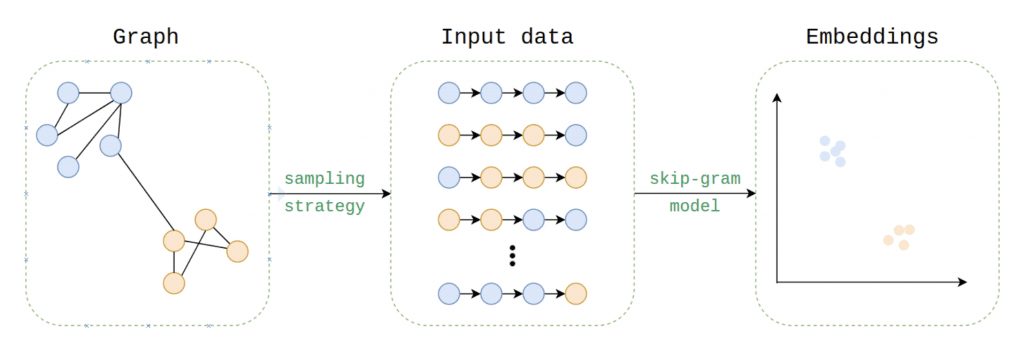
First introduced in 2014 by Perozzi et al. as DeepWalk, this family of models (which also includes the popular node2Vec) generates a series of nodes from a random walk of length k starting at a given node v and measures similarity via the most frequently visited nodes.
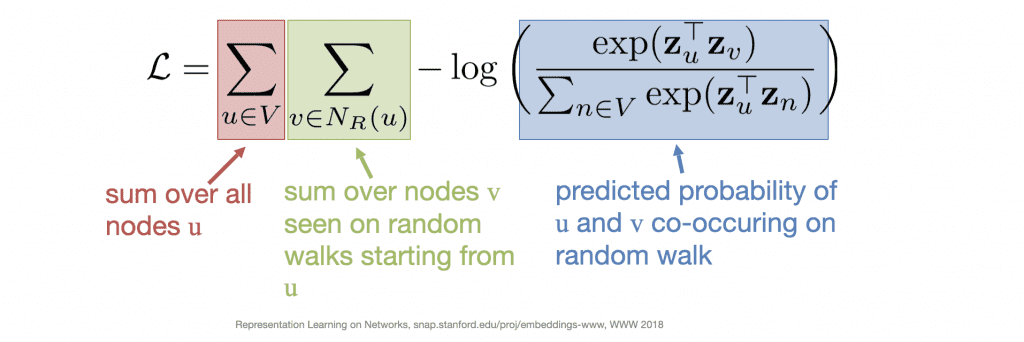
Similarity: For a pair of nodes v, u, the node u is frequently visited by a random walk starting at v
Encoding: Minimize L based on the probability that v, u co-occur in a random walk.
By treating these random walks as a series of co-occurring elements, this collected data can easily be implemented in a skip-gram model, much like word2Vec does with a series of words to generate word embeddings.
Additional Methods
While there are many graph embedding methods I did not cover here, the most notable of which must be that of graph neural networks (gnn), specifically those which implement a message-passing architecture (which at the time of writing this blog has proven to be the most effective architecture to date). The GNN method truly deserves a post of its own, which I will cover in a future blog.
Applications of Graph Embeddings
Now that we’ve seen how graph embeddings are generated, we can finally begin to consider the various ways they can be applied to generate value for your use case. Below we will examine 3 powerful ways graph embeddings can drive this value for you.
1st example: Vector similarity
The simplest and most obvious use for any kind of embedding method is being able to precisely measure the similarity between two vectors. This has a number of practical applications such as recommendation engines or generating measurable similarity relationships within a graph database.
This also enables the embedding space for a given graph to be compressed and represented on a 2/3-D plot, providing a powerful visualization tool.

2nd Example: Downstream Machine Learning Tasks
By far one of the most common uses for node embedding is to use them as upstream inputs for a machine learning pipeline. By allowing the model to produce features for a classification task, you avoid the pitfalls associated with hand-engineered features and instead use your most effective engineered features in combination with a d-dimensional set of embeddings to better capture your underlying data, and then pass that additional interconnected information to the downstream supervised prediction task.
These embeddings can also be used in an unsupervised setting by applying unsupervised methods to the underlying embedding vectors. This can be useful for tasks like nearest-neighbor recommendation engines, clustering visualizations, or community detection within a group of nodes.
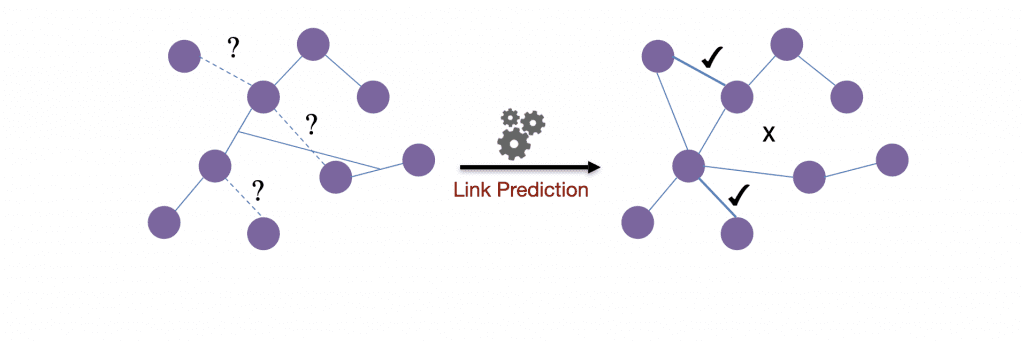
3rd Example: Link Prediction
In addition to the methods mentioned above, another powerful use case for graph embeddings is using them to predict additional relationships within the graph itself. By combing the embedding vectors with a supervised classifier, we can attempt to predict where we may add novel relationships within our graph, enabling us to suggest new products to a given user or new friends they may want to connect with in their social network.
Conclusion
The value of graph embeddings is in their ability to capture the underlying interconnectedness of a graph, the very thing that makes graph data so powerful for modern data analytics. With this, we can enhance a number of tasks that can deliver exceptional value in countless use cases. When we begin to understand how much everything we interact with on an everyday basis ultimately can be represented as a graph, the power of being able to represent that graph in a mathematically manipulatable space becomes clear.
For more on how to create these graph embeddings for your data, check out Neo4j’s Graph Data Science Library to see how to easily implement the techniques mentioned here.
In the next installment of this blog, we will look at how graph neural networks enable us to embed heterogenous graphs and then ultimately look at how to apply heterogeneous graph embeddings to knowledge graphs to generate even more value.
Find related articles on graph algorithms including ones on closeness centrality, graph traversal algorithms, and betweenness centrality algorithms, and LLM Pipelines / Graph Data Science Pipelines / Data Science Pipeline Steps. Also check out this article on Conductance Graph Community Detection: Python Examples.
Credit
A big thank you to Stanford University for making the images seen in this post available and accessible to the public. You can learn more about Stanford’s work with graphs at snap.stanford.edu.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: