CONTACT US
Easy Neo4j GraphQL Serverless Deployment with SST

Deploying a Neo4j GraphQL server to the cloud has never been easier thanks to an SST serverless GraphQL template that requires minimal changes. Follow this guide to have your Neo4j GraphQL API running in less than 15 minutes.
To learn more about the advantages of using GraphQL for all your API requirements, see this blog about cloud AppDev with GraphQL Relay. If you are new to graphs and Neo4j you can also learn more about what is Neo4j and what is a Graph Database.
Pre-requisites for Neo4j GraphQL Cloud Server
For this example we will be using AWS serverless GraphQL, using the Neo4j version. For the the AWS GraphQL serverless deployment we will need:
- A Neo4j database (we picked AuraDB to host it)
- AWS IAM credentials locally configured
- Node.js 14 and npm 7
Setup a test NeO4j GraphQL Database in AuraDB
Following this Create Database example. I picked Movies for this example.
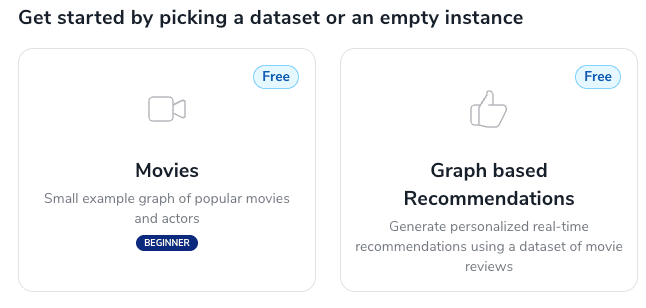
After the database is up and running, download the Username and Password as a .env file.
Setting up the GraphQL Neo4j Project
Create a new project in your favorite IDE (we’ll use WebStorm)
run npx create-sst@latest --template=examples/graphql-apollo
Name your project and when it is done cd into the project folder.
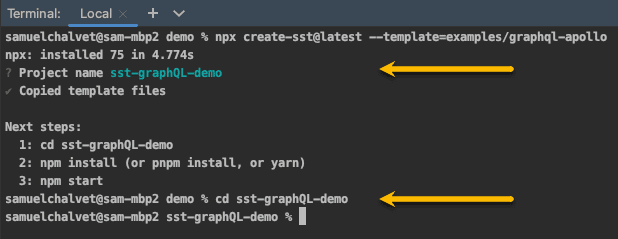
Finally, run npm install and npm install apollo-server-lambda and you have your Apollo GraphQL serverless environment set up., using the Neo4j GraphQL library.
Setting up the Credentials
Replace the .env content in our project with the credentials in the file you downloaded from AuraDB
In stacks/index.ts we’ll need to set those credentials as environment variables so that our Lambda can see them once deployed.
Add this object to setDefaultFunctionProps()
environment: {
NEO4J_URI: process.env.NEO4J_URI ?? '',
NEO4J_USERNAME: process.env.NEO4J_USERNAME ?? '',
NEO4J_PASSWORD: process.env.NEO4J_PASSWORD ?? '',
},
NOTE: In production, these Credentials should be stored securely in AWS Parameter Store or something similar.
Now your GraphQL and Neo4j project is setup and ready for the next step, configuration.
Configuring our Stack to Deploy our Neo4j and GraphQL API
SST is set up as a mono repo in which you configure and deploy many stacks. It generates the Cloud Formation which sets up all of our infrastructures. For more info see Infrastructure as Code.
SST greatly facilitates the relationship between different stacks, allowing us to easily reference anything created in a different stack.
The index.ts file is where we configure application-wide settings such as tags or environment variables. It is also where we determine the order in which we deploy the stacks, which is vital when we have stacks that are dependent on others.
For example, I would first deploy the stacks that create my S3 buckets and my authentication so that the other stacks can reference those for access permissions etc.
In our case, with this simple demo, index.ts doesn’t need further changes because it is already set to deploy our MyStack stack which is where the GraphQLAPI is configured.
The MyStack.ts is also ready to go as we won’t need to make any further configuration changes on your Neo4j and GraphQL API outside of what was supplied by the template we used.
Notice, however, that the MyStack is deploying a GraphQLAPI server with a handler located here: "functions/lambda.handler"
That will be our next step.
Setting up the Lambda function to Run our Neo4j GraphQL Apollo Server
This is our Lambda function that when deployed will start up a single instance of our Apollo Server, for the GraphQL Lambda serverless implementation.
The template we are using is not configured to use the specific Neo4j GraphQL so we will need to make some changes to use the correct Driver and use the Neo4j Schema.
Declaring the Environment Variables
First, let’s pull in our env variables as global variables:
const NEO4J_URI = process.env.NEO4J_URI ?? '';
const NEO4J_USERNAME = process.env.NEO4J_USERNAME ?? '';
const NEO4J_PASSWORD = process.env.NEO4J_PASSWORD ?? '';
Setting up the Neo4j Driver and Schema
We need to install and import the Neo4jGraphQL class
import { Neo4jGraphQL } from '@neo4j/graphql';
const neo4j = require("neo4j-driver");
Run npm install @neo4j/graphql and npm install neo4j-driver
Then declare the driver and the neoSchema
const driver = neo4j.driver(NEO4J_URI, neo4j.auth.basic(NEO4J_USERNAME, NEO4J_PASSWORD));
const neoSchema = new Neo4jGraphQL({ typeDefs, driver });
setting up the Neo4j GraphQL Apollo server
The way the template is currently set up, the Apollo server is created and the handler is exported. However, we want to use the Neo4j GraphQL Schema, and that requires an Async call first, so we’ll wrap the Apollo Server inside that call:
const initServer = async () => {
return await neoSchema.getSchema().then((schema) => {
const server = new ApolloServer({
schema,
context: ({ event }) => ({ req: event }),
introspection: false,
});
return server.createHandler();
});
};
Setting up the Handler
Our last step is to set up the handler that get’s invoked when the API is called. It should return a server handler for the Apollo server we just configured.
export const handler = async (event: { requestContext: any; }, context: Context, callback: Callback<any>) => {
const apolloServerHandler = await initServer();
return apolloServerHandler(
{
...event,
requestContext: event.requestContext || {},
},
context,
callback
);
};
Final touches: Updating your typeDefs
Today, we’ll just hard code our Neo4j GraphQL schema, however to best leverage GraphQL serverless Lambda, I would recommend running another Lambda set to run periodically using the Neo4j introspector to save the typeDefs to Dynamo or S3. Then we can just load it up when we start our GraphQL server so that it will always have an up-to-date schema.
If you are using the basic movie DB that Neo4j Offers, you can just paste this in:
const typeDefs = gql`
interface ActedInProperties @relationshipProperties {
roles: [String]!
}
type Movie {
peopleActedIn: [Person!]! @relationship(type: "ACTED_IN", direction: IN, properties: "ActedInProperties")
peopleDirected: [Person!]! @relationship(type: "DIRECTED", direction: IN)
peopleProduced: [Person!]! @relationship(type: "PRODUCED", direction: IN)
peopleReviewed: [Person!]! @relationship(type: "REVIEWED", direction: IN, properties: "ReviewedProperties")
peopleWrote: [Person!]! @relationship(type: "WROTE", direction: IN)
released: BigInt!
tagline: String
title: String!
}
type Person {
actedInMovies: [Movie!]! @relationship(type: "ACTED_IN", direction: OUT, properties: "ActedInProperties")
born: BigInt
directedMovies: [Movie!]! @relationship(type: "DIRECTED", direction: OUT)
followsPeople: [Person!]! @relationship(type: "FOLLOWS", direction: OUT)
name: String!
peopleFollows: [Person!]! @relationship(type: "FOLLOWS", direction: IN)
producedMovies: [Movie!]! @relationship(type: "PRODUCED", direction: OUT)
reviewedMovies: [Movie!]! @relationship(type: "REVIEWED", direction: OUT, properties: "ReviewedProperties")
wroteMovies: [Movie!]! @relationship(type: "WROTE", direction: OUT)
}
interface ReviewedProperties @relationshipProperties {
rating: BigInt!
summary: String!
}
`;Running SST for the First Time
We are now ready to deploy our Apollo Neo4j GraphQL server to AWS!
Provided you have your AWS credentials properly setup (see pre-requisites above) you should be able to run npm run start
Pick a stage name like sst-graphql-demo
SST will now use our configurations to create all of the resources we need in AWS.
Once it is done deploying, your server will be running in a single instance of Lambda and you will find your ApiEndpoint in the log output. For example:
Stack sst-graphql-demo-sst-graphQL-demo-MyStack
Status: deployed
Outputs:
ApiEndpoint: https://51fsPuajt3.execute-api.us-east-1.amazonaws.com
You can now query your database:
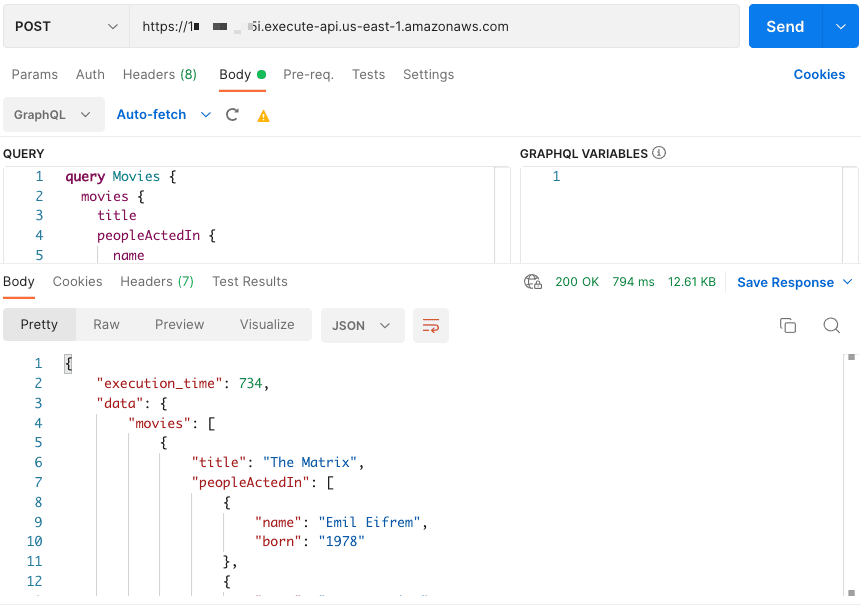
Why pick Serverless GraphQL?
Moving to serverless is cheaper than running a server full-time, there is also no server administration needed as this is all managed for you. Furthermore building this serverlessly makes it highly scalable because the load balancing is automatically handled and your Lambda can be executed concurrently many many times over, then decommissioned once it is no longer needed. For GraphQL with Neo4j an SST, this drives a lot of cost out of projects while increasing elegance and simplicity.
Final Results
If you followed this walkthrough correctly this is what your Neo4j GraphQL lambda.ts should look like:
import { gql, ApolloServer } from "apollo-server-lambda";
import { Neo4jGraphQL } from '@neo4j/graphql';
import { Context, Callback } from "aws-lambda";
const neo4j = require("neo4j-driver");
const NEO4J_URI = process.env.NEO4J_URI ?? '';
const NEO4J_USERNAME = process.env.NEO4J_USERNAME ?? '';
const NEO4J_PASSWORD = process.env.NEO4J_PASSWORD ?? '';
const typeDefs = gql`
interface ActedInProperties @relationshipProperties {
roles: [String]!
}
type Movie {
peopleActedIn: [Person!]! @relationship(type: "ACTED_IN", direction: IN, properties: "ActedInProperties")
peopleDirected: [Person!]! @relationship(type: "DIRECTED", direction: IN)
peopleProduced: [Person!]! @relationship(type: "PRODUCED", direction: IN)
peopleReviewed: [Person!]! @relationship(type: "REVIEWED", direction: IN, properties: "ReviewedProperties")
peopleWrote: [Person!]! @relationship(type: "WROTE", direction: IN)
released: BigInt!
tagline: String
title: String!
}
type Person {
actedInMovies: [Movie!]! @relationship(type: "ACTED_IN", direction: OUT, properties: "ActedInProperties")
born: BigInt
directedMovies: [Movie!]! @relationship(type: "DIRECTED", direction: OUT)
followsPeople: [Person!]! @relationship(type: "FOLLOWS", direction: OUT)
name: String!
peopleFollows: [Person!]! @relationship(type: "FOLLOWS", direction: IN)
producedMovies: [Movie!]! @relationship(type: "PRODUCED", direction: OUT)
reviewedMovies: [Movie!]! @relationship(type: "REVIEWED", direction: OUT, properties: "ReviewedProperties")
wroteMovies: [Movie!]! @relationship(type: "WROTE", direction: OUT)
}
interface ReviewedProperties @relationshipProperties {
rating: BigInt!
summary: String!
}
`;
const resolvers = {
Query: {
hello: () => "Hello, New World!",
},
};
const driver = neo4j.driver(NEO4J_URI, neo4j.auth.basic(NEO4J_USERNAME, NEO4J_PASSWORD));
const neoSchema = new Neo4jGraphQL({typeDefs, driver});
// Neo4j Graphql server
const initServer = async () => {
return await neoSchema.getSchema().then((schema) => {
const server = new ApolloServer({
schema,
context: ({event}) => ({req: event}),
introspection: false,
});
return server.createHandler();
});
};
export const handler = async (event: any, context: Context, callback: Callback<any>) => {
const apolloServerHandler = await initServer();
return apolloServerHandler(
{
...event,
requestContext: event.requestContext || {},
},
context,
callback
);
};
Conclusion
We were able to see that starting with SST’s Apollo template we were able to easily adapt it to work with the Neo4j GraphQL server and have it up and running in no time. This combination of Neo4j, GraphQL and serverless is invaluable for modern development
The flexibility of serverless and SST means that this sort of solution is always a great place to start, and it can be easily tweaked and changed as the project goes on and the requirements evolve.
Read Other Graphable AppDev Articles:
- What is an AWS Serverless Function?
- How to Configure an AWS Serverless API
- Graph AppDev with GraphQL Relay
- Application-driven Graph Schema Design
- The Power of Graph-centered AppDdev – Graph Database Applications
- Streamlit tutorial for building graph apps
- How to build a Domo app using React
Other Helpful Articles:
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: