CONTACT US
Cloud AppDev Power with GraphQL Relay – Clear 4 Step Relay.dev Example

In Graph database application development, particularly in the cloud, choosing the optimal architecture like GraphQL Relay can make or break a project’s success. Some time ago, Facebook released the Flux application architecture pattern for building user interfaces. While Facebook themselves recommend using the Redux or MobX implementations for the UI portion, there is still a significant gap in how to manage the critical capability of fetching data from the server and managing the flow of data. This is where Relay.dev becomes invaluable as part of an overall cloud-based graph database AppDev architecture. As a framework it has all of the most important best practices for managing the state and data side of the AppDev equation. It also does this uniquely by wiring up the data as a kind of logical graph database, by leveraging GraphQL Relay. In this way, it utilizes the power and flexibility of graph to localize the changes at the component level on the client side, avoiding costly server-side operations and traffic, in an optimized fashion that the web-client can easily manage.
GraphQL Relay Helps with Data Challenges
The are any number of data-related challenges when it comes to developing cloud-based, graph database apps. For example, when one writes code in React, more often than not the developer needs to tweak the data to make it fit specific components. By reusing components as parts of other components, through composability (rather than inheritance), it makes it harder to just drop them in place. Particularly without Relay.dev this often requires changes to the server code to make the data fit which introduces unhelpful coupling, making the application more brittle than it should be. Another example in this context is that network hops and data processing can mount as the app evolves, negatively impacting app performance. Yet another example is that the database schema itself can become difficult to change and manage, particularly using traditional data stores (e.g. SQL databases). A last example is the difficulty of updating highly coupled relational data. Much like the benefits of graph databases themselves (e.g. Neo4j), Relay.dev has the advantages of offering a state and data management framework based on GraphQL, with all the benefits of performance, flexibility, agility by leveraging what is ultimately a kind of logical graph database on which to manage the data portions of the application.
GraphQL Relay Core Components and their Advantages
- Caching / Batching – This is critical for driving performance, but handling caching and batching manually would be a significant amount of work for a developer to to create on their own. Relay makes it easy to parse the graph tree, to prime the local cache, differentiate queries, and make queries smaller.
- Querying Data
- Colocation – Since the queries live next to the view, Relay.dev enables developers to query fragments that match a single view, and then consolidate them into a single query ultimately driving the cost of queries down.
- Declarative – The expressive language structure of GraphQL enables developers to query by describing desired outcomes (e.g. “this is what it should look like”) as opposed to using imperative query languages such as SQL where it is a statement of specific action (e.g. “this is what it should do”).
- Data Integrity/Leaks – There is always a danger in over-exposing your precise database structure publicly. With declarative graph query languages (e.g. GQL, Cypher or even the declarative part of Gremlin), they are simply too specific and powerful when communicating data requirements directly to and through the storage engine. The potential risk of using it directly on cloud-based app databases is of exposing the database structure publicly via the query statements if that engine was ever hacked. This is often resolved by shielding the data source behind a service layer which is helpful, but Relay.dev resolves this more directly and elegantly by using GraphQL as a layer of separation, through its runtime engine, which ultimately provides more flexibility.
- Mutation – Relay.dev uses mutation instead of immutability. Immutability has the advantages of providing more protection from bugs, and it also makes it easier to understand and track changes. Mutation on the other hand has the advantages of enabling optimistic updates, improving data consistency, reducing errors related to memory leaks as well as enhancing performance when copying large objects.
Getting started with GraphQL Relay
As a way to start working with Relay.dev to better understand how it all works, you can follow these steps:
Step 1: Start with a simple directory structure like this:
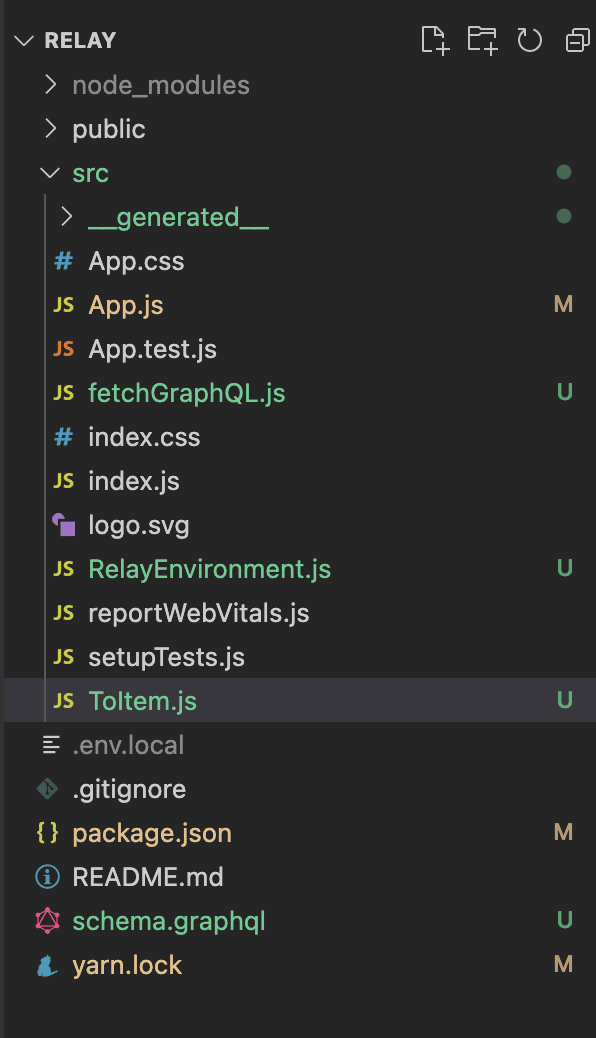
…begin by fetching some data by creating a fetchFunction:
const response = await fetch(URL, {
method: 'POST',
headers: {},
body: JSON.stringify({
query: text,
variables,
}),
});
To fetch data, alternatively you could use the Fetch API with a GraphQL Relay query as the body of the POST request (Note- for this approach, the GraphQL query has to be a String).
Step 2: Setting up the Relay.dev Environment
The Relay.dev Environment is used to encapsulate the definition used to wire up the data as well as to cache data, perform queries and more:
export default new Environment({
network: Network.create(fetchFunction),
store: new Store(new RecordSource()),
});
Step 3: Set up caching
Reusing this previous fetchFunction logic, you could enhance your approach with a caching strategy:
const fromCache = cache.get(queryID, variables);
if (fromCache !== null) {
return fromCache;
}
...
And then, if nothing can be found in the cache then enable a data request instead:return const response = await fetch(URL, GraphQLQuery)
.then(response => {
...
Finally, after that data request is successful and if the cache was empty, then set the local cache.if(response)
cache.set(queryID, variables, response);
In order to reuse locally cached data Relay.dev needs a fetchPolicy with a loadQuery function. The policy is used to determine if the query needs to check the locale cache, or whether a request should be made over the network.
The default strategy “store-or-network” enforces the reuse of locally cached data and only performs a request if no data is found or if it is stale.
More Relay.dev policies can be found here: https://relay.dev/docs/api-reference/use-query-loader/
Step 4: Experiment with the advantages of collocation
Relay.dev utilizes fragments to enable linking the view to the query. Here one can create a fragment directly inside the component that uses that specific data, thus collocating the query.
const {graphql, useFragment} = require('react-relay');
function CustomUserComponent(props) {
const data = useFragment(
graphql`
fragment Custom_component_data on Person {
name
},
props.person
return (
{data.name}
);
}
In order to be able to fetch data, the fragment needs to have a root query since it cannot be fetched by itself.const personQuery = graphql`
query person($id: ID!) {
person(personID: $id) {
birthYear
# Include child fragment:
…Custom_component_data
}
}
`;
And lastly, request the data in the parent container:const preloadedQuery = loadQuery(RelayEnvironment, personQuery)
function App(props) {
const data = usePreloadedQuery(personQuery, preloadedQuery);
}
return (
<>
{/* Render child component, passing the fragment reference: */}
</>
);
GraphQL Relay Drives AppDev Success
When it comes to using the Flux pattern with GraphQL Relay, a fully featured implementation such as Relay.dev simplifies the task of managing GraphQL communication. It also transforms and optimizes queries, simplifies cache and batch management and even state management, as well as improving failure handling. Relay.dev leverages the power and advantages of graph database technology, while abstracting the communication which drives a more secure application while significantly improving development efficiency.
Read Other Graphable AppDev Articles:
- What is an AWS Serverless Function?
- How to Configure an AWS Serverless API
- Application-driven Graph Schema Design
- The Power of Graph-centered AppDdev – Graph Database Applications
- Neo4j GraphQL Serverless Apps with SST
- Streamlit tutorial for building graph apps
- How to build a Domo app using React
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: