CONTACT US
What is an AWS Serverless Function and Why is it So Powerful?

An AWS serverless function, also known as AWS Lambda, is like a microserver that can start itself up extremely quickly and then run as needed for short periods of time. It is event-driven, meaning that it only runs when it is triggered and they are designed to perform some very particular action in response to this event. It is “serverless” because AWS handles all of the underlying infrastructure for you.
What is an AWS Serverless Function?
At its core, an AWS serverless function is an encapsulated bit of code that performs a discreet task, and is only active when it is being called and used. It can run code written in a variety of different programming languages, and can also support Docker containers.
They can run concurrently, meaning that many instances of the same AWS serverless function can be running in parallel at the same time. However, there’s no idling cost to this concurrency; once each has done its job, it turns itself off and releases the resources that it was using. Due to their short lifespan, they work best when designed to do one thing very well.

AWS Lambda
Serverless Function
We’ll talk more about the different events that can trigger an AWS serverless function, but for now, we’ll just say that they are extremely versatile in their functionality and can practically eliminate the bottlenecks with which non-serverless architectures constantly struggle.
Trivia: Did you know? The greek letter lambda (λ) is used in physics and chemistry to represent the “decay constant” of a material and calculate its half-life. It is an apt symbol for these AWS serverless functions that only live for a short amount of time.
What Benefits Does an AWS Serverless Architecture Offer?
AWS services that are referred to as “serverless” are largely managed by AWS. This means that we don’t need to worry about updating to the latest version of the various layers of the server stack that actually power the Lambda functions, nor do we need to concern ourselves with the newest software patches, or compatibility issues. Everything is already configured and handled by AWS. As the developer, you just need to focus on your application logic.
Furthermore, scaling based on demand is also automatically handled for us. Serverless services are also pay-for-use services often billed by the millisecond of use or the exact amount of data transferred to optimize the cost which can keep project expense down overall.
When designing a serverless architecture, there needs to be a paradigm shift in how we think. Each part of the whole becomes more of a standalone piece and is not so tightly intertwined with the rest. We want to be able to easily replace, change or scale up a specific aspect of the application without impacting the rest of it.

Using tools and cutlery as an analogy, previously we had always created applications that functioned like a multi-tool. These applications needed to handle just about everything. Continuing with the analogy, the issue with this approach is that if you want to eat a steak, a multi-tool knife probably isn’t the best option and you end up with many options in the multi-tool that may work, but that are not an ideal fit.
For example, on the multi-tool knife, you could not really add serrations to the blade or adjust its length, both of which would improve its effectiveness. The optimal knife for cutting a steak is, well… a steak knife, and it is designed to do that one thing extremely well. Likewise, we want the different parts of our app to function like that steak knife, designed and optimized specifically for the required task.
Thus the essence of serverless architecture is that you do not need to waste your time and energy on managing and configuring resources, creating the constantly available elements of a multi-tool, and instead you can focus on what matters- developing a number of loosely coupled elements, each created to do exactly what it needs to do, all of which fit together to form your app.
What are other AWS Serverless Services?
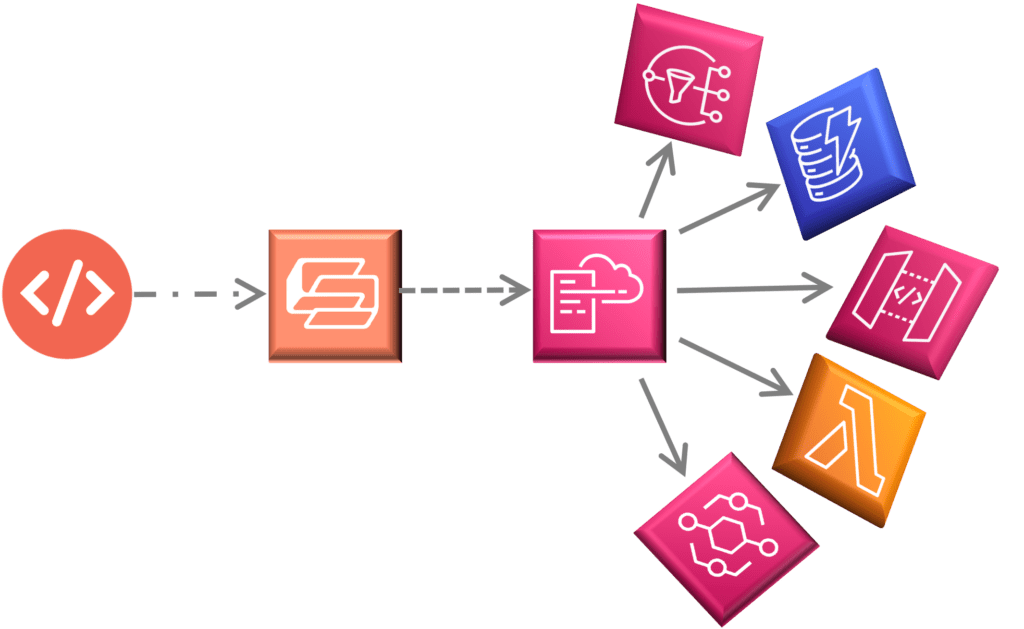
On top of AWS serverless functions (AWS Lambda), AWS offers many other managed serverless services that we can best think of almost as puzzle pieces. Each piece can handle or solve a specific type of need such as computing, storing data, and application integration. AWS gives us a quick overview of them on their serverless page.
These services pair well together because they are preconfigured to support very fast communication and data transfers between themselves.
Because these are AWS managed, highly available, and they automatically scale for us, it becomes very easy to use these services as tools in our kit. We can mix and match the services to build out applications, and all we need to worry about is writing the code and logic to solve our use case, not mange the server stack supporting the AWS lambda function.
How to Create an AWS Serverless Function?
The simplest way to start creating a AWS serverless function is to log into your AWS instance and use the AWS Console to pick one of the many preset blueprints offered. These templates are set up in NodeJS or Python and preconfigured to hook into other AWS serverless services.
The UI offers a decent code editor, and the ability to configure your function, add in environmental variables, create and test events, hook into other triggers, access logs, etc. It is a great place to start or to build a proof of concept.
Alternatively- and this represents our preferred method for many cloud contexts- is to use a framework like SST which enables you to create Infrastructure as Code (IaC) and build full-stack applications that you can deploy to AWS with a simple command. SST provides users with a streamlined experience for defining IaC. It takes care of most boilerplate code and formatting, which allows us, the developers, to focus on defining the pieces of the infrastructure that we care about. SST then generates JSON formatted data which AWS CloudFormation then interprets to create everything you need. SST also greatly facilitates referencing and connecting different parts of your application across any number of stacks.
For example, using SST the code block below creates two things: a function with a dynamic name using the stage variable (e.g. dev-send-sms or prod-send-sms) and the required policy statement (permission) to allow our function to send SMS messages from a given phone number passed using an environment variable. We also configured the allocated memory to 512MB, set the timeout of 15 seconds and defined the runtime that we’ll use for the function as Node.js 16. The actual code that will be executed when the function is called is in a different file: `${source_path}/send_sms.handler`
let sns_perm = new iam.PolicyStatement({
actions: ["sns:Publish"],
effect: iam.Effect.ALLOW,
resources: ["*"],
});
let send_sms = new Function(stack, "send_sms_id", {
environment: {
ORIGINATION_NUMBER: CONFIG.ORIGINATION_NUMBER,
},
handler: `${source_path}/send_sms.handler`, // my code entry point
functionName: `${stack.stage}-send-sms`,
description: `Sends an SMS message to a user`,
memorySize: 512,
timeout: 15,
runtime: 'nodejs16.x',
permissions: [sns_perm]
});
Using IaC you can create and configure all the different resources that you will need and then easily deploy them to different staging environments such as production, staging, and dev. This ensures that you have exactly the same environment running in each context, which has a significant positive impact in the development process and CI/CD pipeline.
For more on creating Infrastructure as Code check out this post about building a Neo4j GraphQL serverless deployment with SST.
How To Use and Trigger AWS Serverless Functions
AWS serverless functions are event-driven, which means that they start themselves when something happens. There is a wide variety of ways to trigger a function, including, but in no way limited to:
- HTTPS requests, using Amazon API Gateway
- File or image upload to an Amazon S3
- Email or SMS sent or received using Amazon SQS
- Scheduled event using Amazon EventBridge
- DynamoDB Streams using near real-time data polling
- Or we can chain a large number of AWS Serverless Functions together using IFTTT logic with AWS Step Functions.
With the array of options available to us, it is very easy to set up an event-driven serverless architecture that can seamlessly integrate with existing applications. AWS maintains a full list of ways to trigger an AWS Serverless Function that you can read about.
Easily Creating an API in the AWS Serverless Framework
Another valuable use case in the AWS serverless framework is creating an AWS serverless API, in combination with Amazon’s API Gateway. It is incredibly fast and easy to set up a very inexpensive and effective API. You simply need to write a bit of code to define what each API endpoint does and configure how you want your routing to work. The AWS serverless framework handles everything else, including load balancing.
Setting Your Serverless Function as the Target of an EventBridge Rule
Probably the easiest way to trigger a function is to have it be the target of an EventBridge rule. EventBridge allows you to create rules that try to match a specific event pattern or run on a schedule. You can create the rule, then pick the target, in our case we want to invoke an AWS Lambda function. Finally, you can then define what will be sent to your function via an event payload.
For example, reusing our send_sms function that we defined earlier, I can create an EventBridge rule that will run every day and trigger my function with a specific payload:
const daily_msg_rule = new Cron(stack, "daily_msg_rule_id", {
schedule: "rate(1 day)", // triggers everyday
job: {
function: send_sms, // target lambda function
cdk: {
target: {
event: RuleTargetInput.fromObject({
message: "Daily reminder to do something!",
destination: "+18885554444",
}),
},
},
},
enabled: true,
});
This function will receive an event with the message to send and the destination phone number.
How to Embed a Serverless Application as a Nested Application?
By following serverless architecture principles, we can create code that can essentially functions like micro applications, where each encapsulated lambda function does a discreet task or set of tasks very well. Furthermore, by using Infrastructure as Code we can then publish the CloudFormation template that we use for our app. Once done, we are in a position to include our serverless application as a nested application inside any other deployments that we create.
For example, I created a group of AWS serverless functions that take in some HTML and convert it into a PDF file. The file is saved temporarily to an S3 bucket and returns the file location as an output. I can deploy this little app and make its CloudFormation template available. In the future, if I need this functionality for any of the other apps I am building, I can reference my HTML-to-PDF Lambda function and it will be redeployed as part of the new app that I am creating. This HTML-to-PDF “app” is now nested into this new app.
Conclusion
Hopefully, we have demonstrated the power of these Lambda functions. Building your future applications using the AWS serverless framework minimizes the time you spend configuring and maintaining your environments, and maximizes the efficiency and effectiveness of each component of your app.
Read Other Graphable AppDev Articles:
- How to Configure an AWS Serverless API
- Application-driven Graph Schema Design
- The Power of Graph-centered AppDdev – Graph Database Applications
- Graph AppDev with GraphQL Relay
- Neo4j GraphQL Serverless Apps with SST
- Streamlit tutorial for building graph apps
- How to build a Domo app using React
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: