CONTACT US
What Is a Knowledge Graph? Powering Business With Graphs [Video]

What Is a Knowledge Graph?
The question: what is a knowledge graph? is hotly debated because it’s still an emerging technology. But fundamentally, it represents the real world and shows how entities are connected. And it’s created and stored in a graph database.
Before diving deeper into knowledge graphs, it’s important to know the fundamentals of graph databases. The two are distinct but related. A graph database is simply a data store that requires development effort to create an asset that can be used as the underpinning of a business application. The knowledge graph is the asset that’s created and stored in the graph database. It ultimately becomes invaluable to organizations.
The best example we’ve found is similar to how relational databases could store, for example, sales data that can become even more valuable when, for example, a customer relationship management system (CRM) leverages that data to organize, track, and process our sales pipelines. In the same way, a knowledge graph is an asset that sits on top of a graph database.
A knowledge graph essentially becomes a digital twin of an organization, or an aspect of an organization. It represents the real world, and how entities (people, partners, sales, products, locations – think of your dimensions in your business) are actually connected in real life.
Knowledge Graphs Mirror Human Cognition
A point of caution: Knowledge graphs are not designed to be transactional storage systems, but rather higher-order systems distilling information from our transactions. No human would remember all the conditions surrounding them every time they perform addition. Things such as time of day, the weather, if the addition was done with pen and paper, or on a calculator.
The only knowledge the brain needs to retain is that 2 plus 2 equals 4. Any remaining extraneous information is irrelevant and does not have to be stored for the person to know the result of adding 2 and 2 together. Effectively, the process of acquiring knowledge is one where repeated practice distills key pieces of information that get connected and retained with irrelevant data erased from the memory.
The same holds true for businesses seeking to leverage knowledge graphs. As an example, we can take a restaurant that is trying to build a knowledge graph to connect different wines with menu items that can be personalized for different customers.
One way of solving this problem would be to link ingredients and flavor palettes with wine bouquets manually using human knowledge. While time-consuming, expert sommeliers and chefs working together could use their knowledge to create relationships in a spreadsheet that can be built into the knowledge graph. A small subsection of the graph will look like the image below.
For example, the chefs and sommeliers work on tagging red wines that have an earthy flavor to be paired with steak and linking a dry white wine with the sea bass could be done one wine and one entree at a time. These subject matter experts can even rate the strength of the pairings and these can be stored on the relationships (indicated by the thickness of the lines).
On the surface, wine-to-entrees are relationships that reflect human knowledge, and we’ve now moved this expert knowledge from a single mind into our knowledge graph. Moving out from our simple wines-to-entries relationship, we can now make a second order connection between entree ingredients and the individuals notes of the wine bouquet. With this second order connection, we can add new wines to the menu nightly without having to manually review each one, using their tasting notes and dish ingredients to infer the best pairings between them.
The expert sommelier is unlikely to be able to memorize every relationship between entree and wine, but has a fundamental understanding of the collection of ingredients that pair with the collective notes of any particular bouquet. To replicate this, new entrees or wines can be integrated into the knowledge graph with different similarity metrics can be used to find the best pairings for them.
Another way of building a knowledge graph is to use customer history to find the best relationships between wine and entrees. The knowledge graph itself would not need to store all the transactions from all customers. Instead, the historical purchase patterns of customers and their ratings.
By finding the highest rated customer experiences, the probability that an entree should pair with a given wine can be determined, without the need for explicit knowledge of relationships between entree ingredient and wine bouquet. This process can be done using analytics and will require minimal amounts of human intervention, letting patterns within the data guide the way. But, the caveat here is whether the restaurant patron is the best source of knowledge in this space, and that the aggregate behavior of the consumer will reveal the best pairings overall.
Most importantly, the flexibility of the knowledge graph allows us to leverage all three of these options in whatever way is best for the business. We can customize the importance of the expert knowledge, the inferred matches, and transaction history to achieve the perfect recommendations from our highly connected data, all updating in real time, returning instantaneously results based on millions of wines and food pairings in the above example.
Unstructured data and Knowledge Graphs
While beyond the scope of this article, Knowledge Graphs can also leverage unstructured data alongside structured data to achieve their full potential. If companies combine free-form text such as reviews, articles, 10-Ks, legislation, technical documents etc. and connect the meaning and value of that data with their structured data, a Knowledge Graph has the potential to have a much wider and more significant impact on the business.
By using methods from Natural Language Processing (NLP) to detect key topics, sentiments, and extract additional context, hidden relationships can be discovered to drive new insights for the organization.
What Are Knowledge Graphs Used for?
Now that we’ve covered the details of knowledge graphs, let’s explore: What are knowledge graphs used for? From powering chatbots to content management, the potential for knowledge graphs to drive businesses is nearly limitless. Here is a short list of the potential use cases for knowledge graphs in business:
- Bill-of-Materials
- Research and Development Tracking and Whitespacing
- Augmented Intelligence for Personalization
- Recommendation Engines
- Automated Content Tagging
Simply, the ability to be able to connect information together holds tremendous power in the digital space. In upcoming blogs we will take a deeper dives into some of these use cases. You can also read our recent blogs that explore: What is a recommendation engine? and building recommendation engines.
Video Transcript: What Is a Knowledge Graph? (Click to Read)
[00:00:00] Kyle McNamara: Welcome to the Knowledge Graphs 101 webinar for Graphable, subtitled: “What are they, how do you make one and how can they benefit your organization?” I figured I’d get started by actually doing a little bit of an intro here. I’m Kyle McNamara, CEO of Graphable. I’ve got Will Evans as well, VP of Strategy and Innovation. I’ll be doing a bit of an overview, and then Will will be doing a demonstration.
To give you a thumbnail on Graphable and our core competencies, just so you know who we are, we focus on Neo4j graph databases, graph analytics, graph data science, machine learning, natural language processing, knowledge graphs, graph-based application development, so custom apps with graph at the center, traditional analytics, as well as data integration and data strategy.
If you have questions along the way, there should be a question/answer button at the bottom. It looks like that little image that I set on there. You can ask your question and we’ll get to as many as we can at the end of the session.
To get rolling, in order to put knowledge graphs in context, we want to start with the question “What are graph databases and why are they needed?”
Another question you could start with is just, where do they even come from? If you think about the history, the mathematics around network science have been around since the 1700s, but it really hasn’t been, if you look at the X axis here, since 5 or 10 years ago that it started to become more pervasive in the enterprise. If you look at the interest level in graph databases over the last 5 to 10 years, it’s really outstripped all the other data stores by a significant factor.
An important question: what are they and how are they different? I’ve boiled this down to the question of both intent and magnitude. When I say intent, I don’t mean what’s the intention inside the data, but what’s the intent of the application?
For recommendations, or is it finding who knows who in terms of fraud analysis? It’s the intent to find connectedness and relevance, and it’s the magnitude of any significance. Because there’s a lot you can do in relational databases mimicking what a graph can do, but once you get to any kind of scale, it becomes much more difficult to make it performant.
We can use a classic graph database use case like recommendations. There are a lot of people with skills around relational databases, and the first question they ask is “Why not just use a traditional relational database?” That’s pretty easy to answer.
It’s inefficient for these kinds of “graphy,” so-called, use cases that involve connectedness and relevance. The SQL language itself is not structured or optimized for finding relevance or connectedness or directionality in the data. Even the objects themselves, tables and rows, it’s just not set up for that in mind.
On the other hand, graph databases principally store only data relating to the kinds of questions being asked, and they’re optimized for asking those kinds of questions relating to relevance, connectedness, directionality.
Data stored natively as a connected network in an actual native graph database like Neo4j – most of the other databases out there are not native graph databases, and that has different implications – but it makes it quick, often in the milliseconds, to traverse millions and even billions of entities and relationships. It enables us to quickly and efficiently find relevance between those entities.
I found this – I think it was a blog article from Neo4j from years ago, showing this great example of relational versus graph. It’s a simple one, but it’s very telling. If I want to find how Alice is related to the departments in the organization, I’m going to have to typically go through some kind of lookup table or a join table and look at the associated SQL statement. It’s two or three times the length of a Cypher statement, which is purpose-built to find that connectedness or relevance.
You look down here in the graph model below, you can see Alice could belong to a future or past department, and it’s very easy, right within the structure, let alone the Cypher statement, to find that connectedness.
I found a great article called “The Continuing Rise of Graph Databases” by ZDNet, and I thought they really captured it well, the idea that “using stores with data models that best align with the problem at hand is becoming increasingly popular and understood.”
So it’s not about using graph databases for everything, but rather, a lot of the questions being asked today, that organizations are asking of their data,[00:05:00] and at the scale they’re asking it – so that question of intent and magnitude – it requires data to be stored as a connected network in a graph database.
Now we’ve given a little bit of background on the graph database side of things in order to position knowledge graphs, let’s dig into that side of things. What are knowledge graphs?
The question is debated, and for good reason – you’re looking at a chart here from Gartner, the Hype Cycle for Emerging Technologies. To underscore the fact that it is an emerging technology, in 2018, this is where, if you look down here, Gartner positions knowledge graphs as a concept in the enterprise. So it’s something that’s unfolding right in front of us, and there’s going to be a variety of perspectives, and we’ll bring ours here today.
The question is, how do these knowledge graphs relate to graph databases? Because they’re interrelated but they’re not the same.
Like all databases, a graph database is simply a data store that requires development effort to create an asset that can be used as the underpinning of a business application. The knowledge graph is the asset itself ultimately becomes invaluable to organizations is the asset that is created and stored in a graph database.
A knowledge graph essentially becomes a digital twin of an organization, or an aspect of an organization. Think of HR, for example. That’s in the sense that it more accurately represents the real world, how entities (people, partners, sales, products, locations – think of your dimensions in your business) are actually connected in real life.
This in turn opens the door to answering questions that were difficult, if not impossible, to answer at scale before. With the intent of finding relevance and connectedness at today’s scale of data, a certain magnitude, this is where it becomes really, really valuable.
Finally, Graphable in particular is pioneering using unstructured data to achieve the true potential of knowledge graphs, and our approach we believe distinctly sets knowledge graphs apart from other graph database applications. And it’s important because I believe Gartner said it was around 80% of your data is actually semi-structured and unstructured data, and in most cases, it’s really not being used. There’s huge value and potential for differentiation and competitive advantage, but it’s very difficult to work with.
We believe leading edge natural language processing and machine learning used to identify and store the parts and meaning of the unstructured text is critical to building an actual knowledge graph. It’s very difficult to do, though, and we’ll talk about how we can lower the bar significantly in the demonstration.
Enriching existing domain data with internal and external sources. Think I might want to enrich my internal domain information with legislation externally, ConceptNet, Wikidata, maybe a financial data store that is available publicly that translates acronyms to the full name, makes it specific to my domain.
And then leveraging ontologies/taxonomies – that sounds fancy, but really they’re maps of things to bring domain relevant points of view to your knowledge graph, points of entry to the knowledge graph, and really efficiency in traversing and just additional order to that knowledge graph.
Lastly, knowledge graphs should be self-learning. This is really looking towards the future. We can use knowledge graphs to discover the things that we think we know we want to understand about that data, but once you’ve set something up like a knowledge graph with your unstructured data, we can use machine learning to really uncover the unknowns, highly valuable unknowns that are buried in this massive data that’s inside our organization.
A practical example of a knowledge graph – little-known, but massive scale – is Google. There’s not a lot of official information about how Google created and maintained its knowledge graph, but as of 2016, there was something like 60 billion connected facts there. The question is, how does Google surface value from such a knowledge graph for its users?
[00:10:00] For one, it underpins their newest version of its content ranking algorithm called RankBrain, which is much more effective than it’s ever been as a result of the knowledge graph. And for end users doing a search, a highly relevant thumbnail is just one example of the value.That information, when you do a search, actually suggests a top result with an info card to the right. If I look at “Neo4j” as a search term, you notice this info card on the right, which is basically appearing at lightning speed based on this knowledge graph. This is a really good, concrete example of where knowledge graphs are already in use today.
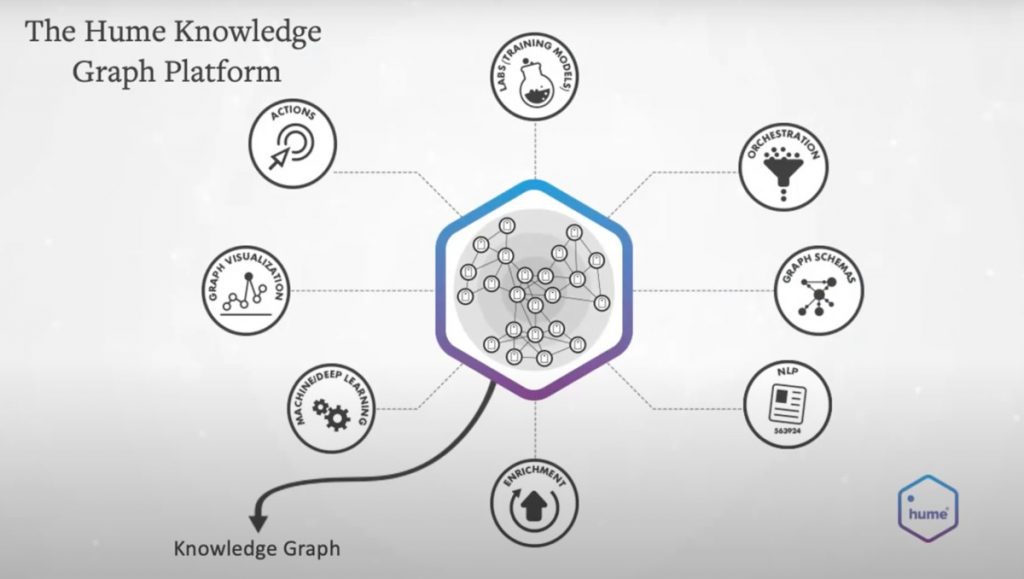
At Graphable, we are the exclusive reseller of GraphAware’s Hume knowledge graph platform. That’s what we’re going to demonstrate today – not because it’s the only way to build a knowledge graph, but there are a set of capabilities that are really required to be able to manage/grow over time, at scale, a knowledge graph that’s really going to change the landscape of your organization.
I’ll just step through the set of capabilities that you’ll see today through Will’s demonstration momentarily so you get a sense of the kinds of things that are required, or even helpful, to get to the place where I’ve got an actual knowledge graph in motion in my organization.
One of those things is the Hume Labs. You need some way to transfer the main expertise of your people internally – you hire people who are experts – and get that knowledge into the machine. Through a user-based, very simple-to-use user interface, collaborative environment, your lawyers or your doctors or whoever can actually annotate and link unstructured documents in a way that teaches the machine about your domain.
Probably the most important thing is it takes existing models like Stanford NLP that come as part of the platform and combine them with your unique and specific domain information that’s context-specific to your business to drive up the overall accuracy and recall. And those are the two key measures in NLP. Accuracy and recall are the things that matter, and we see way above industry standard using this Labs capability.
Orchestration is the ability to create an ecosystem of data. Whether that means I’m pulling from a Neo4j cluster and I’m pulling from a message queue of some kind or I want to apply machine learning or some Cypher statement or set of statements along the way, or write up to an Elasticsearch index – this really complex ecosystem of points that represent the knowledge graph being created, that’s what Orchestra is for, and you’ll see an example of that.
Graph schemas. Again, most people understand graph databases are considered a schemaless database, but in reality, humans don’t understand databases without a schema. So from the perspective of creating the database, designing it, understanding it, interacting with it, schemas are really valuable. And to our knowledge, we’re first to market with that capability.
NLP. This is IT and expertise. We’ve written, rewritten algorithms, come up with ways of assembling algorithms as far as ingesting unstructured data – all kinds of capabilities in the platform that is IT, and we also offer expertise. Natural language processing and unstructured data is never going to be a big red “easy” button activity, and we bring that expertise to the table in these contexts as well.
Enrichment. We talked about that before. You’re essentially compounding the value of your data with external or even internal knowledge bases.
Machine and deep learning. Now, we’re not talking about just using machine learning to build out this knowledge graph, but to also, in turn, find the things that you may not even know that you need to know. There’s hidden value in finding the connectedness of your information across huge organizations. I’m going to give you a really good example of that towards the end about a cruise company that had a really interesting use case where it’s important to that context.
Graph visualization, best in class visualization. If you’ve got millions of nodes, that’s not as helpful, if you’re an analyst or a business user, to try to find out what matters to you. So that’s got to be a really important part of it.
And then actions – the ability to encapsulate really valuable and in some cases very technical capabilities by right-clicking. I could be a nontechnical user and run a community detection algorithm on a set of nodes to drive out insights that I could never have done on my own.[00:15:00] We’ll show you some examples of what that can be as well.
Next, we’re going to transition to a demonstration with Will. We’ve actually got a craft beer knowledge graph, because we love craft beers here at Graphable, and we just thought it was a nice non-industry-specific way for people to get a sense of how they might apply these techniques to their unique environments. I’ve transitioned to Will, and I guess Will, at this point, if you could go ahead and start sharing.
Will Evans: Thanks, Kyle. As Kyle mentioned, what we’re going to be running through here is a craft beer demo. Really, what we want to do as we walk through this is we want to start at the end with the result. Then we’re going to walk forwards through all the steps that we had to take along the way to get there. We want to highlight the power of having a knowledge graph.
In our craft beer demo, we’re looking at a couple pretty simple things, and it’s representative of a number of different use cases. What we have in our dataset is users who have reviewed beers, and the beers have a brewer and a style. This use case really, though it’s interesting to us in and of itself, represents a lot of broader similarity use cases, like finding similar high-performing employees, finding communities of feedback, recommending products, use cases around research in terms of recommending relevant research to the appropriate person at the appropriate time.
Really what a lot of these things share in common is that they’re sparse high-dimensional datasets. Unlike some of the datasets that you see in more standard machine learning algorithms, we only have one or two reviews on average per beer, and each user has only on average reviewed one or two beers.
So if we stick with our standard machine learning algorithms where we try to say, “Okay, you reviewed basically three beers, and then let’s find other people that recommended those beers,” we’re very likely to just end up recommending the most popular beers because they’re by definition going to have the most overlap. And that’s okay, but it’s not the most effective way that we can go about this.
What we can do using graph is actually even go further and increase the dimensionality of our system. We can do that with things like pulling valuable information from our unstructured data using NLP, which is what Kyle talked about in the middle of his presentation.
What’s the result of all that effort? If we start with a beer and look at something like a personal favorite of mine, the Blue Moon Belgian White, we can do something quite simple, like run an action to find a similar beer. Because we’re domain experts, we can decide and actually weight in our graph the importance of flavor, texture, and appearance.
These are basically percentages, and I say flavor is the most important to me, texture is second most, and appearance is really not that important. I don’t care that my beer looks the same. I just want it to taste and have the same mouthfeel.
As I submit that, what we’re going to do is leverage all of the information in our graph around the millions of reviews, the hundreds of instances of unstructured data that are being pulled back, and we’re going to make a number of recommendations based on what we’ve requested in that weighting.
As we look at these results, we see that there’s some similarity here. We have a Blanche De Brooklyn, which is also a wheat beer, similar to our Blue Moon Belgian White. We’ve got a Hefeweizen, which is another very similar wheat beer.
But we also have a couple of potentially odd results, like a Tire Chaser IPA. We wouldn’t necessarily recommend – if you just asked me off the top of my head for recommendations similar to a Belgian White, I wouldn’t come up with an IPA necessarily. But that’s in our graph, and we’ll understand at the end why we’re making recommendations like that.
Similarly, what we’re able to do is we can also start from a different view. We can look at a user – take our standard user, MikeDrinksBeer – and we’ll see what he’s reviewed. As we look through this, we can see that Mike’s had about 20 beers and he’s reviewed them, so he’s one of our higher reviewing users. And he’s drinking beers within certain categories.
There’s a couple different categories, but he specifically is looking at something like an American IPA. As we’re leveraging the dimensionality of our dataset, what we can actually do is things like split out the tokens in our
[00:20:00] style so that we see Mike looking at a number of American Blonde Ale and American IPA, and he’s got an American Double. What we’re looking at here is maybe it’s not actually the IPA piece that Mike cares about; it’s the American piece. So as we go and we recommend beers for Mike, we may want to not just stick with the style, but we can actually split that style into individual tokens and make new recommendations.As we look at our new recommendations, some are within the same style, but many are in different styles. We’re looking at American Doubles or American Stouts, and they’re favoring that because we know that he is preferring American beers. That’s all because we’re leveraging the dimensionality of our data and not just trying to run averages and produce our most reviewed beers.
Now let’s take a step back and say, okay, if we wanted to do these two seemingly simple things that we made simple with all of this effort, how would we do that? And it all starts with Labs, as Kyle mentioned. Labs is the place where we can bring our domain expertise into the system and then leverage it at scale against our data. Using a representative set of documents, we can perform annotation tasks. Annotation is identifying so that we can extract the entities and the relationships that we care about.
So if I come in here, I can see that we have aspects like “light orange color,” which is a piece of appearance. So I’ll identify that and match all within my document set. I can say “citrusy.” Maybe this is a flavor. I want to annotate that as a flavor. As we keep going through, we can say there’s orangey taste, so let’s annotate that as one last example as a flavor. We don’t have a glass type in this review, but we could also annotate glass type.
Once we have our domain expertise, our beer experts come through and define the important pieces – instances of flavor, appearance, texture, and glass type – we can then create a version of that, which is basically creating a training set. For those of you who have very advanced NLP capabilities, you can actually export and download training data so you can run entity relationship extraction models or named entity extraction models. Or within Hume, we can actually one-click create an entity extraction model, which I have previously done, and create a skill.
A skill is basically – think of it like an Amazon Alexa skill or something similar where we have a tool that we want to leverage in other places in the application. We’ve done all this effort tagging our data with our domain experts, and we want to be able to leverage it someplace else, so we’ll create a skill to be able to do that. Once we’ve created that skill, we go back to our knowledge graph and we can start leveraging Orchestra and start filling in our data based on our NLP.
As you can see, we’re actually pulling this from existing Cypher within Neo4j, and we have our entity extraction skill, which you can see is still called the “beer skill.” It’s going to pull out entities and submerged entities and other annotations, but then also within Hume, we have a standard piece of IP, which is Hume Text Rank, where we’re using basically the sentence structure within a graph to identify keywords.
As we see when we go back to our schema, these all fit into our graph alongside our structured data. We have our users who have written reviews, and those reviews mention a beer, and those beers are in brewers and styles. All of that’s structured data, and it’s sitting alongside, almost indistinguishable from data that we’ve extracted with NLP, like texture, glass type, flavor, appearance, and keyword.
That really comes down to what we see as the strongest power of knowledge graphs, where we’ve been able to take domain expertise, extract extremely valuable pieces of information from our unstructured data, and store it alongside our structured data in the graph to leverage both of them.
As we’re making recommendations, we’re going to care about both the review scores – so looking at the score on palate and taste and aroma and appearance – as well as what kind of appearance was there? Because when we’re recommending beers to Mike, he might prefer really hazy beers, whereas Sally may prefer really clear beers and rate them differently. We want to be able to leverage those pieces of information.
As we come back into our visualization and dive into this in a little bit more detail, I just want to highlight the power of this in terms of leveraging our annotations at scale. When I created this demo, I annotated about 100 reviews and found six examples of glass type.
When I pull this up and you see that we have 400 instances of glass type within the system, we can see that we have a[00:25:00] pint-sized Pilsner glass, a 12-ounce glass tumbler, a wheat glass, a 12-ounce brown glass, a pint bottle. We have all these different instances because our NLP model has been able to identify how a glass is referenced within text and extract that from our unstructured data.
The same thing has happened with our appearance, flavor, and texture. I didn’t annotate – this is not a dictionary lookup where we’ve said 517 things are appearance within a graph. We can bootstrap with a dictionary, but in the end we’re going to want to create a model, and Hume lets you do that very quickly.
Now if we go back to our original similarity use case, we have our Blue Moon Belgian White and we’ll run our same query here to get the same results. Now once we get these results, I want to take the next step and actually explain the similarity because, as we mentioned, there are some results coming up here that don’t necessarily make sense to us off the top of our head.
We have some ones that do, but if we come out to this Brooklyn East India Pale Ale, maybe what I want to do is explain the similarity between these two, because an East IPA is not intuitively similar to me to a Blue Moon.
So I’m going to come and explain similarity, and because of all of this data is in a graph and we have that unstructured data alongside our structured data, we can actually see what pieces of the reviews are being extracted and that describe these two beers, as well as actually visualize how important they are to the two reviews.
As we start looking through here, we see that we have some instances of taste. We’ve got a taste of coriander, which is very light. We have a weight of about 11,000, which is small on our scale. But we have some very popular instances of citrus and orange and sweet, as well as they’re both hazy and cloudy beers, but they’re also light and smooth.
So now, even though an IPA and a Belgian White don’t off the top of our head seem very similar, once we’re able to look at the unstructured data connecting the two of them, we can see that these actually would be incredibly good recommendations.
If we take a step back here again and think about from beginning to end what we just did here, we were able to capture our domain expertise into the system, into the platform, and leverage it at scale.
We’ve seen instances of organizations where they’ve tried to do this and they’ve gone through all this effort to annotate documents and ended up with an Excel file or a TSV file stored on someone’s laptop after spending hundreds of manhours and massive investment on getting their legal team to annotate regulatory documents. That’s a really dangerous way to play. Within Hume, all of that information is stored and versioned within the system.
We’ve then taken that expertise and been able to leverage it against our unstructured data and store the results into our database. Now it’s something that we can leverage automatically – not automatically, but very easily, as Kyle was mentioning, against applications. This application, this database – here, we’re using actions, but we might have an application where we have a frontend that’s recommending beers, or we’re recommending products or reviewing our employees or whatever it may be. That data is all available to us.
Then most importantly, we’ve taken this amount of effort, which is normally measured on a months and years spectrum, and moved it down to days and weeks. We’ve taken the time to value from long to incredibly palatable, which is increasing the ROI on any investment into knowledge graphs and NLP.
That’s one of the biggest things that we see, and actually, we did a presentation at NODES 2020 recently about investment into NLP and being able to start with smaller bite-size chunks so that we can get value rather than trying to boil the ocean. Cutting down that effort and leveraging NLP on our unstructured data to create more dimensions on our sparse datasets allows us to achieve incredibly powerful results, and we can do that much faster with Hume.
Back to you, Kyle.
Kyle McNamara: Thanks, Will. I’m going to go ahead and share out. You should be seeing that demo slide. I’m advancing now to some examples of knowledge graph use cases. This gets into the question of, how does this drive value for your unique organization? This is about planting seeds and giving you examples of what other companies and other organizations have done, leveraging this emerging technology.
[00:30:00] For example, we actually worked around a concept of, with a cancer institute, how could you match patients to trials? It’s hard to imagine a more important activity than taking a family member of yours and being able to connect them somehow to an unfolding trial that could uniquely address what they’re facing. There’s really never been anything like a knowledge graph to be able to drive that kind of outcome. So there’s a really cool and impactful example. You get lots of unstructured data with patient records and trial information and so forth.Next, defense. We’ve got an example of managing across millions of research articles and emerging defense requirements and looking at how we can match those up. Huge, huge level of effort without having a capability like this to build and manage a knowledge graph and deal with and actually work on the ingestion side as well.
Energy, mapping oil wells to parts, maintenance, documentation. Lots of unstructured.
Cruise company. I’m going to pause on this one because I mentioned it earlier in the overview. Connecting emerging legislation with massive fuel buys across disparate holding companies. I thought this was one of the most interesting examples I’ve ever heard. We’re talking about a multibillion dollar company.
One holding company is responsible for doing large fuel buys to save money, multi-year, and they went ahead and did a fuel buy at a certain grade. Meanwhile, where they sail in Europe, legislation was released at the same time that prohibited that fuel grade that they just bought a multi-year purchase of.
It was a real-life example. If there was some way to harvest things like unstructured data, legislation, that could really be impactful to my business – like tangibly impactful to my business, my bottom line – connect that up with activities and other unstructured data from inside of the rest of my company, and then somehow suggest that to an executive to look at – that is a needle in a haystack that would be incredibly valuable to know about. Not possible really at scale before knowledge graphs.
Retail. Enriched and more targeted ecommerce recommendations. If you think about products, some products are very simple. Some have lots of unstructured data. All of them have reviews, which are unstructured and related kinds of information. Others have documentation. Bringing in that incredibly important unstructured side of the equation can make all the difference.
HR department, identifying top 100 must-keep employees out of tens of thousands. If you think about the job of an HR department to really make sure they keep the workforce intact and happy, it’s really important to be able to somehow understand, maybe out of tens of thousands of employees, who are the ones who are having the outsized impact on our organization?
And if we lost them, they would also have an outsized impact on our organization, maybe going to a competitor, for example. By harvesting all kinds of unstructured data from inside the company and understanding who are these top contributors, it’s a huge value-add.
Banking, managing duplicative compliance efforts across the world. This is a massive, massive cost to banks around the world. Similar kinds of compliance, different kinds of – other kinds of contexts in which they have to do the same thing over and over.
Fleets, managing parts and maintenance and maintenance documentation.
Another example is security. We talked about defense already, but intelligence, policing. There’s all kinds of really important applications for this. Identifying bad actors or situations or contexts in time to make a difference.
So those are just some examples. There’s tons more, but these are some of the ones that we’ve come across over time. We thought it would be helpful and valuable just to plant some seeds.
From here, I’m going to bring it in for a landing by doing a quick poll and then we’ll go to question and answer. I’m going to launch a poll. It’s very simple. It’s yes/no, “Did this webinar help me understand knowledge graphs better?” This is my first time actually using this. Hopefully it works out and you can go ahead and start answering this. Then we will advance to the Q&A. We’ll give this just a minute and start looking at some of the questions.
One of the questions that was asked and answered – and any question that was not answered live,[00:35:00] that was answered in writing, you can see it under the “Answered” tab within the Q&A window. There was one in there, “Are there memory limitations to processing?” Will has actually answered that question. I’m going to go ahead and see if there’s another one here. You can read that one.
“How do we handle temporal data? Would like to see how that plays out in knowledge graphs.” You’re welcome for the presentation. Temporal data is obviously a really, really significant topic, and the implications inside of graph are not insignificant either.
I will say this: there are techniques that we’ve used and are using and are evolving, actually, to really use temporal data in a graph context. There might be other contexts where you could use time series databases and stuff for it, but there’s amazing applications for temporal data inside of graph. I think it’s probably beyond the scope of this particular call, but if you’d like to find out more and find out what we’ve done and how we’ve solved for that challenge, we’d love to talk more about that.
Another question that came up: “How do you handle tracking changes in the information? Are you still able to show a change history?” Within Hume, the platform, it’s definitely tracking those changes and versions over time. You can certainly excise the data over time that you don’t want, but by default there’s definitely an ability to keep track of what was so that you can see what is and what’s changing over time.
I’m going to leave that one up because they’ve also answered that in writing. This time it doesn’t look like there’s a ton of other questions out there. I would like to leave a little bit of time. I’m going to end the poll now. Thanks, everybody. Looks like overall we’ve got a favorable sense of the value of the presentation, so thank you for that feedback.
I’d like to point out that you can reach out to us anytime through the website. We’ve actually got a blog that you can sign up for. It has our events as well as our blog articles on related topics. And you can reach out directly to Matt Braham. There’s his email as well as our overall phone number. If you didn’t get your question answered in time, or you want to talk to us in more detail about any questions at all, we’d be happy to do that. Matt can set that up. We’ll get the right people on the phone to have that discussion.
Overall, thanks for spending your lunch with us. I hope everybody’s staying safe, and we look forward to an opportunity to catch you on the next webinar. Thanks, everybody.
Check out a powerful new natural language interface to your graph database / knowledge graph that enables your non-technical users to ask natural language questions right to the database itself (meet Sherlock™ from Graphable).
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: