CONTACT US
Exploring Product Lifecycle Graphs: Example

In our blog Next-Gen Basket Analysis with Graph we looked at product-to-product relationships by compressing the high-dimensional relationships of attributes, co-purchasing, and descriptions extracted from keywords. The next logical step is to explore another graph database use case related to product lifecycle management. Essentially, this is the data that collects all the building blocks of a product and its lifecycle, tracking them all the way into the hands of the consumer. Inherently complicated, a product lifecycle graph has to include bills-of-materials, manufacturing processes, logistics, and the point-of-sale (see example product lifecycle graph below). These data contain many many-to-many relationships that have to be tracked across both time and space, with many transformations along the way.
The Product Lifecycle is Inherently Complex
Where data structures are concerned, the usual sources of complexity and complication in all things data are: 1) “many-to-many” relationships and 2) sequences and hierarchies. Many-to-many relationships become necessary when a single data element can be connected to many other entities, and these connections in turn are related to many other entities. These relationships are especially complicated if they are “conditioned” where for example, A is connected to X when X is connected to B, but not if X is connected to C. The second issue is sequential data. This could be in the forms of steps or hierarchies. Steps will allow the creation of a path or journey, where a component might start in a given state and then eventually go through a series of transformations before eventually emerging as a final product.
Bill of Materials. A single product is almost always made up of many different components. In many cases, these components and raw materials are sourced from different vendors. Sourcing components from different vendors keeps the supply running, preventing overall production disruptions even in the event that one or more individual component source is disrupted. But, multi-sourced product components also mean that there will be added variance to the product lifecycle data, making it critical to know which components went into which batches of products. In addition, many products can share the same component or sets of components, which in and of themselves could come from a variety of different sources. Not to mention, sometimes these components are sold as individual replacement parts in store or online. What you end up with are many-to-many relationship patterns where the relationship between components, products, and sources is often deeply complex.
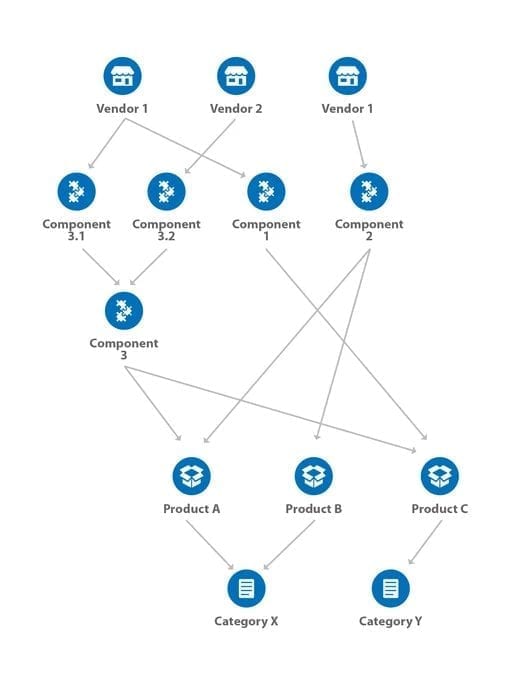
Bill-of-materials stored as a graph.
Manufacturing and the Production Line. Much like the bill-of-materials, some products might share the same manufacturing steps, but with potentially different costs or procedures. This creates a situation where many-to-many relationships are necessary. For one product, the same component might need more time to install than another, depending on the vendor source. Some parts might have to undergo certain processes before being placed into the product. Each product has an assembly process with steps that need to completed in order for the product to come together. To make things more difficult, the components that go into a single product could be manufactured by multiple manufacturers that reside in different geographical locations. If these parts are needed for repairs, then they can also be sold as standalone products with assigned SKU numbers. At this point, this data set is already complex, we now have to layer on the “lifecycle” aspect of these products. For most companies, products evolve over time. As technology advances and customer behavior and preferences change, products might get new packaging, or be built with new parts or the processing procedures are updated.
Logistics and Distribution. When products move across the distribution network, for some, it might be something as simple as going direct-to-customer from the manufacturing plant. For many larger organizations, products usually have to go through many steps before eventually reaching the customer. While the initial starting point for any product is the manufacturer, products usually move on to regional distribution centers. Depending on whether the organization sells through brick-and-mortar locations or is digital only or is an omni-channel seller, the level of complexity in the logistics network will vary. Omni-channel retailers usually have to balance in-store inventory with digital inventory. This means having sufficient inventory and safety stock of the assortment to reduce the number of lost sales. This requires the tracking of the outflow of product for digital fulfillment and inflows of product from returns for digital and in-store purchase.
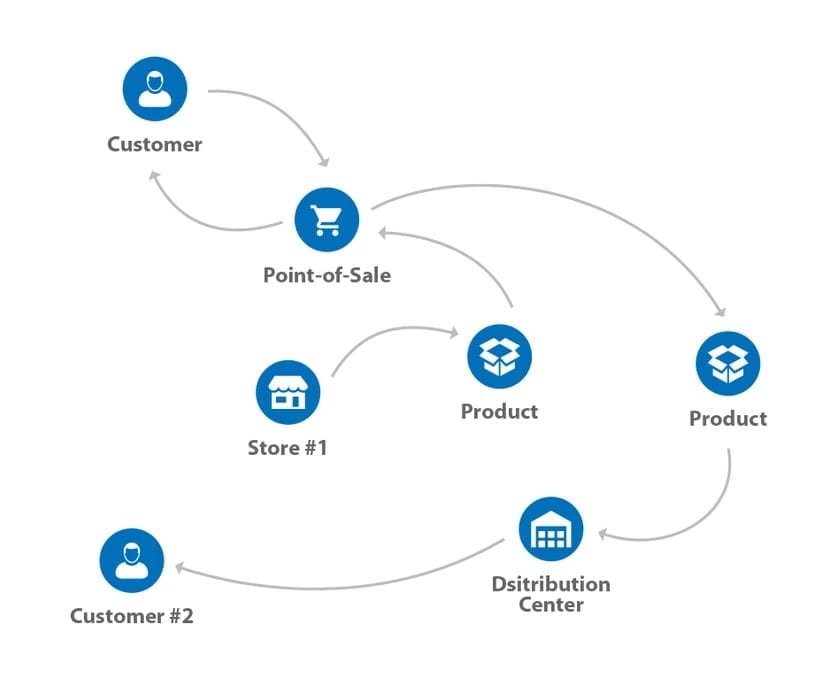
Point of Sale. In today’s omni-channel retail environment, the point-of-sale is no longer a short journey of a browsing customer seeing a product in-store, paying for it, and then leaving with the product in-hand. With online browsing and the ability to buy online and pick up in-store (BOPIS) or return in-store (BORIS), inventory tracking is essential to the success of any omni-channel retailer. Especially with flexible fulfillment, SKUs could move between stores and distribution centers, knowing when, where, and how each unit was moved becomes critical to keeping the customer base happy.
Why Use Property Graphs such as Neo4j?
Product lifecycles are, by nature, journeys that different entities undergo, starting with raw materials and components that are transformed by machine and manual labor, eventually arriving in the hands of the consumer. At its core, product lifecycle data are a series of interconnected pieces of information that span categories, space, and time. Having a mash-up of different data types with many-to-many relationship patterns makes them very difficult to define as rows and columns or key-value pairs. A critical limitation of these so-called “relational” approaches to data storage is the inability to quickly leverage statistics of the connections between entities themselves to gain critical insight into the business.
Graphs such as Neo4j are the best way to accommodate the complexities of these relationships with the ability to store both hierarchical and transactional data simultaneously due to their “schemaless” nature, offering nearly limitless flexibility to the data storage structure.
Product Lifecycle Graph Example
Here is an example of what a product lifecycle graph might look like.
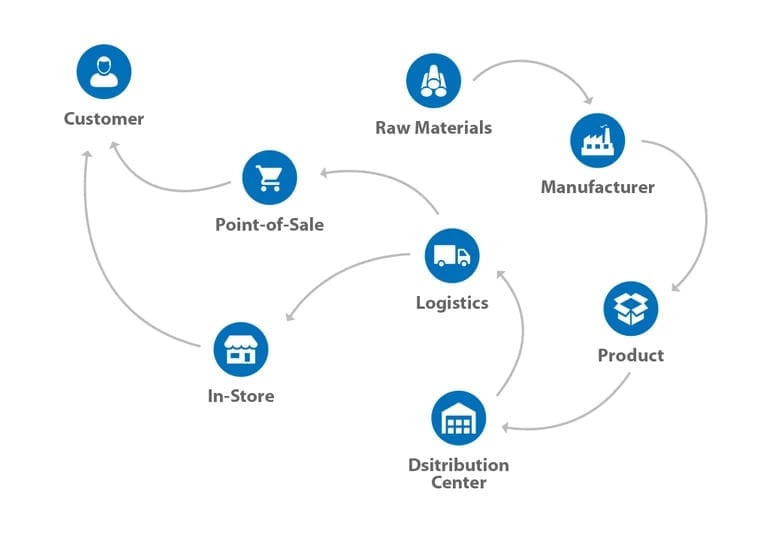
What Does It Solve?
Flexibility from a schema perspective also means that building the Knowledge Graph itself might take a few iterations of draw-and-erase efforts. Graphs are easily “whiteboarded” and align with the way we normally think about connected data semantically, “Product A” – CONTAINS -> “Part B” -UNDERGOES PROCESS -> “Process C” – REQUIRES -> “Amount Time D” and so on. Because of the true relational nature of graph databases, a critical benefit of storing product lifecycle data as knowledge graphs is the ease of data manipulation. Easy data manipulation also means easier data drilldowns and aggregation. In particular, graphs enable aggregation along specific paths, especially helpful in product lifecycle data where the same product might be manufactured through multiple processing paths.
This means having the right software tool that:
-
- Allows you to easily design and re-design multiple iterations of the graph schema;
- Connects your data schema to your knowledge graph;
- Has all the necessary ETL tools to ingests data into your Knowledge Graph; and
- Can also be used to visually and statistically analyze the graph to extract insight.
Once the graph has been built and is up-and-running, there are many different analyses that one is now able to conduct. A an example, we can go back to problem of having multiple process paths for the same product. Assuming completion time is the only metric for success, the goal here would be to see which production path is the “shortest”, both in terms of the number of steps and overall accumulated time. Across all the steps in the product lifecycle that we have covered so far, the “chain” of steps that a product takes along its path to get from raw material into the hands of the customer is complicated and long.
Bringing it All Together with Product Lifecycle Graph Insights
Having the ability to trace the specific paths along its journey is essential to allowing visibility into manufacturing process issues, sourcing problems, customer preferences, and logistics challenges along the way. While the phrase “360 view” might be perhaps overused, a graph that is able to track product lifecycles and eventually sync with customer data is uniquely suited to provide this view. It is important to remember that each iteration of the product might follow a different path where analyzing labor cost, processing time, and quality control is critical to understand what features of the product lifecycle affected customer preferences and purchasing patterns.
Perhaps the most powerful benefit of using graphs to store product lifecycle data is the long “breadcrumb trail” that it creates. Knowing every step in the movement of products end-to-end creates a window into your business, generating insights that can guide decision making. For example, detecting whether a store is becoming a mini redistribution center (e.g. many SKUs being bought in a digital channel and then being routed through this store) is a good Neo4j use case. There might also be patterns linking returns to future sales, where eventually, predictive models could be developed to predict when SKUs should be moved to another store or distribution center before it is bought by a customer.
In future blogs, we will explore additional aspects of the product lifecycle, specifically, manufacturing, logistics, and point-of-sale. In each of these blogs, we will take a deeper look into how a graph database like Neo4j is able to streamline the process of storing data and how it can also serve as a core for your analytics platform, finally delivering on a true 360 view of the business.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: