[REPLAY] In an increasingly competitive world, the quality of your ability to make relevant recommendations is crucial for business success. Using smart, personalized and real-time recommendation engines improves your ability to make better decisions and increase revenue.
Watch the video below to learn how graph technology supercharges your recommendations and similarity engine by leveraging the high-dimensional nature of typical data sets. Discover how graphs (and specifically beer graphs) can help you manage not just mountains of data (customers, products, services, prices, etc.) but also the relationship between them. As an example, we’ll explore beer graphs.
We feature a demo using a real set of sparse and high-dimensional data to make great beer recommendations based on user reviews. Find out how graph technology helps you:
Power more accurate recommendations in real-time
Correlate product, customer, inventory, supplier and social data
Instantly capture new interests from customer visits
Drive recommendations based on user history and profile
By the end of the demo, you will understand how to leverage your datasets for relevant, accurate, and timely analysis through our presentation of graphs, and more specifically, beer graphs. The technical presentation and examples of beer graphs starts at minute 7:35.
Video transcript:
[00:00:00] Joe O’Donnell: All right, good morning. Welcome to Neo4j & Graphable’s webinar, Exploring the World of Beer with Beer Graphs. I’m Joe O’Donnell, and I’m joined today by Will Evans, VP of Consulting and co-founder of Graphable, a Neo4j premiere partner.
What we’ll be sharing with you today is how graph-based solutions are unique in their ability to analyze consumer behavior, improving customer insights that enable more targeted and accurate recommendations in real-time, in a way that was not possible in the past.
A little bit of housekeeping before we get going. If you have any questions along the way, please enter them into the chatbox, as we’ll answer them at the end of the demonstration. Also, please do mute yourself. Thank you very much.
So, what are “graph-based” recommendations? Well, across all industries, graph-based recommendations have fundamentally transformed our everyday lives. Graph-based recommendations are at the core of these and other market and industry disruptors. “People you may know,” advertisements based on your search, movies, songs, shows you may like, products you may want to buy – underneath all of these is graph-powered technology.
So why graph-based? Everyone has traditional or NoSQL database. Why graph databases as opposed to those particular options?
Well, the era of one size fits all databases is over. Specific data problems and applications, either transactional or analytic, have specific needs. There are so many different databases that solve different problems. You no longer have to look at every data problem as a nail and either relational or NoSQL databases as your hammer. It’s all about choosing the right tool for the job.
A graph database is the right tool for the job when it comes to real-time personalized recommendations. Graph databases easily outperform relational and NoSQL data stores for connecting massive customer, product, inventory, and even social sentiment data to gain insight into customer needs and product trends. Moreover, a real-time recommendation engine requires the ability to instantly capture any new interest shown in the customer’s current visit. That’s something that traditional databases can’t accomplish. Matching historical and current session data in real-time is trivial for a graph database like Neo4j.
When making recommendations, time is of the essence. As the connectedness and size of your datasets grow, your relational and NoSQL queries and also non-native graph databases get exponentially slower. The speed, flexibility, and scalability of Neo4j’s graph technology uniquely enables you to deliver on the promise of personalized, real-time recommendations, improving response time from minutes to milliseconds.
So, which data model do you prefer? The one on the left… or the more intuitive one on the right? Not only is Neo4j’s performance thousands of times faster than traditional databases, it requires 10 to 100 times less code. And for business users, it’s a very intuitive way for them to navigate and explore the data, easily communicating what’s going on.
Why the combination of Graphable and Neo4j for graph-based recommendations?
Well, the combination of Neo4j’s graph database and graph data science along with Graphable and Hume provides everything you need for a real-time recommendations framework – everything from data orchestration, including semi-structured and unstructured data, seamless integrations, graph creation, powerful graph analysis, and visualization.
Today, we’re focused on real-time personalized recommendations. However,
[00:05:00] recommendation engines have become a crucial component of modern applications of all types. Companies like UBS use it for risk management, tracking the entire life cycle of data – what its origins are, how it’s evolved and how it’s moved through the organization. Airbnb uses recommendation frameworks to connect all their siloed databases to better understand the relationships between their hosts, customers, locations, etc., so that they serve up the right property for each guest. And Boston Scientific models and analyzes their manufacturing supply chain processes to identify at fault components.
Intelligent recommendation frameworks are used to build a sustainable competitive advantage, giving you an edge when it comes to insights from your data relationships.
Considering the competitive advantage that graph provides in understanding the relationships in your data, as well as in speed and performance, it’s no surprise that graph database is by far the fastest growing category in the database market. And with the leading, most innovative graph technology, along with the largest and strongest community of experts and partners to ensure your success, it’s no surprise that Neo4j is the undisputed leader in graph.
Speaking of subject matter expertise and experience, as one of our premier Partners, Graphable is with you every step of the way to ensure your long-term success with graph.
At this point in time, I’ll hand it over to Will now for the demonstration of Hume, the real-time personalized recommendation framework built on graph database and data science technology. Before I do, though, I’ll just remind you to please put your questions in the chatbox and continue to leave yourself on mute. Will, over to you.
Will Evans: Awesome. Thanks, Joe. Today, what I’m going to cover in this demo is going to be focused on two areas. The main screen that we’ll be looking at will be Hume, which is a graph-powered insights engine built by a company we resell here in the U.S. Hume sits on top of Neo4j, so all of the data is residing in the Neo4j graph database for making our recommendations, and all of the queries and recommendations that we execute are running against Neo4j.
Beer Graph Example
Our use case today is looking at beer graph recommendations. This is a demo that we use pretty frequently. You’ll see when we go into Hume that we have a number of different use cases that we built it out for, but because it’s Cinco de Mayo and because beer graphs are fun, this is just a nice business-agnostic use case to look at.
We want to leverage a set of real beer reviews within Neo4j to make great recommendations and to more broadly demonstrate how graphs (and specifically beer graphs) can help identify similarity in spare, high-dimensional data. We’re going to explore making more accurate recommendations in real-time, correlating product, customer, inventory, supplier, social data, as well as talking about how we can capture new interests from customer visits and drive recommendations based on user history and profile.
As we dive into the use case a little bit more here, finding recommendations and similarity is very powerful for businesses, but it’s often incredibly difficult. I think we all understand how making good recommendations to our customers or having personalized search or finding similarities between objects in our business is always good for business and customer experience. But it’s very difficult, especially in the areas where it would be most beneficial, like systems where you have consumers facing a large product assortment and searching isn’t feasible, but product discovery is desired.
This is because in a lot of cases, the results are actually fewer than the dimensions, and you don’t have the typical aggregation that someone like a Google search has, where they’re looking at a lot of people searching for “grill” and “propane grill” and “gas grill” and “outdoor grill” and “barbeque,” and they all just want to get to the same grill page or go to some consumer who’s selling them grills. But from our perspective, we may have customers on our website searching for pants, and they all want to find a different pair of pants based on what their personal preferences are. So we want to make them good recommendations based on their history.
Most use cases have sparse data that doesn’t lend itself to typical machine learning algorithms,
[00:10:00] and there’s a customer pool of unique individuals with diverse taste profiles.
What we want to be able to do in these recommendations as well is to leverage subject matter expertise. In most cases – in our case, I personally am an expert in beer (and beer graphs), and in most of our cases we have some subject matter expertise within our organizations that we can leverage. So we want to use that to build parameterized dimensional recommendations so we can allow our expert humans to define the key dimensions.
We want to do this because a lot of machine learning is very regressive, where we peg users to their prior state. And as we all know, tastes in beer change over time. Maybe when we started out our beer journeys, we were drinking a lot of light beers and some of the more popular items, but now maybe we’ve shifted to micro beers or IPAs or whatever it might be. That’s something that typical machine learning has problems with, but our experts can understand, and we can bring into our recommendations.
As we look at our dataset more specifically, as Joe mentioned, building this in a traditional database is going to be a very complicated schema or relationship diagram. But in our Neo4j database, our schema is incredibly simple and very intuitive. Through a beer graph, we’re looking at beer as the center of our universe, connected to our reviews, our users, our brewers, and our styles.
If we actually then dive into exploring our data – I’ll shift screens here, put myself down into the corner – we can now see the Hume platform. As I mentioned, we have a number of different use cases in here, from regulation to biology to market analysis, but we’re going to focus today on beer and look at our data through beer graphs.
If we come in here and do just a brief exploration, we can see that we’ve added a few nodes into our schema, which we’ll leverage for the recommendations in terms of some custom named entities that we’ve extracted within Hume. But predominantly we have 1.6 million reviews from our 33,000 users, and we have 66,000 beers.
If we do some quick math there, we can see that we’ve got 1.6 million reviews, 33,000 users, and 66,000 beers, which equates to, just based on multiplication, about one review per user per beer. What this means is that we have very sparse data. If we come in here and run a global action, we can see how many reviews each beer has, and with our 66,000 beers, more than half of them have two reviews or fewer. So we’re not going to get great results just by driving towards averages across our whole dataset because there’s so many beers that just don’t have very many reviews.
Similarly, in the other direction, it makes sense that we see the same pattern, where for most of our users, more than half of them have two or fewer reviews. It’s a slightly longer tail here, actually, than the beers, but it’s still quite concentrated up in the certainly single digit and one to two reviews, which really makes this dataset have the sparse, high-dimensional qualities that we were talking about.
So how do we make these recommendations? Let’s switch back over to PowerPoint. We’ll see that we want to start off by not boiling the ocean. As we talked about, making parameterized dimensional recommendations, we’re going to start with what we like to think of as individual dimensional modules, and we’ll unify them at the end. So we can start by focusing on flavor and make recommendations based on flavor. Then we can add in appearance, and we can add in texture, and we’re going to start aggregating and weighting those together.
Really, at the core of this is avoiding complexity if it’s not needed, because we’ve seen time and time again that by leveraging the power of a graph database within Neo4j, you can achieve good, repeatable results from a hard dataset using a collection of basic techniques. We like to think of these techniques as rule-based+, where it’s not simply a rule-based algorithm, but we’re leveraging that expertise to define our dimensions and then can achieve new and unexpected results beyond that.
Then we can go further, certainly, to do things like clustering algorithms and node2vec and typical graph data science, but they have diminishing returns if you’re using them at the beginning because you end up putting in a whole lot of time before you actually know where your value is and what a baseline for recommendations is. So we recommend actually waiting to do those a little bit later, once you understand the value of making these recommendations or finding the similarity within your organization.
We want to not start this out by simply doing co-review occurrence, basic collaborative filtering. We don’t want to simply recommend beers with the highest scores because we may find beers that have one review but the highest score.
[00:15:00] And we’re going to avoid simply doing basic vector embeddings to find similar reviews because a similar review doesn’t necessarily mean a good recommendation.
We really need to be careful throughout this to prevent narrow or mismatched recommendations, because if people as consumers start seeing the same results over and over again – or worse, if they see results that they don’t like – then that’s a risk to the consumer experience.
This is just an image that we put together to show what we mean by this dimensional recommendation. We’re building a Cypher query that involves a number of different dimensions. Flavor might be one, or appearance might be another, or texture might be another in our system, and we’re going to bring that together to create the expertise for making recommendations.
That was a little teaser, but if we go back over to Hume, we’ll start here now by getting a single beer to start making our recommendations from. I’ll run another global action at the top to bring back a Blue Moon Belgian White, which is one of my personal favorite beers. Then we can make that parameterized dimensional recommendation. Using right-click to navigate on my beer graph, I can actually deploy a custom local action. This is running essentially a parameterized query in the background. You can see that I have my exact image up on the screen. I’ve got my flavor, which I’ll give a custom parameter of 80%, texture 10%, and appearance is 10%. Now we’re running that layered query based on these dimensions to make the recommendations.
If we remember the beer graph model that we brought up earlier, we’re extending out from our Blue Moon Belgian White, to all of our Blue Moon Belgian White reviews, to all of the custom entities within those reviews, to all of the other reviews of those users, and aggregating back to relevant beers based on those keywords.
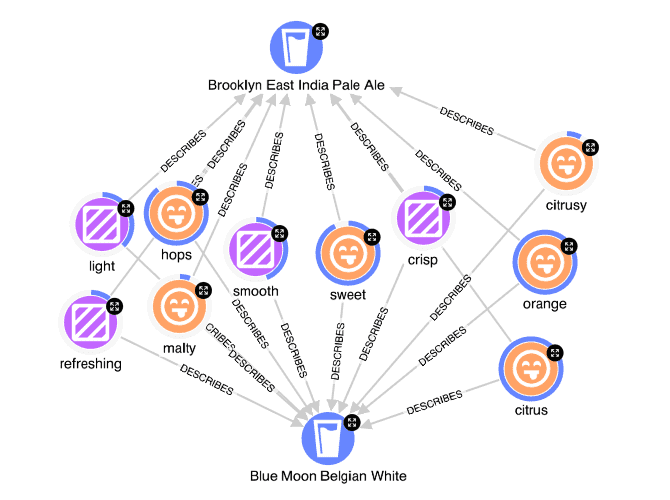
What we can see is that we end up with some very interesting results where, down in the bottom of my graph here, I’ve got my Blue Moon Belgian White, and I’ve recommended another wheat beer, this Blanche De Brooklyn – which makes sense because we assume that two wheat beers are pretty similar. And then we can also see that we’ve got a Hefeweizen, which is another wheat beer, so that starts to make sense. But as we move around further in our graph, we have a Tire Chaser IPA, which is an American IPA. We have this Braggot, which I’ve never personally had. We’ve got a Herbed/Spiced Beer, some Saison or Farmhouse Ale, and we’ve got this Brooklyn East India Pale Ale, which is an English India Pale Ale, which seems very far away from a wheat beer.
So if I think about starting to want to understand how I got to this point – I’ve done my parameterized dimensional query, and now I want to understand, okay, what actually created this Brooklyn East India Pale Ale as a recommendation?
I can select both my beers in the beer graph. I will use the keyboard Command I to take the inverse and just remove some of those from my visualization to keep things nice and clean, and then I can select both of these beers. When I right-click, I will have a different set of local actions available to me because we’re able to specify what nodes or multiple selections they should appear on. And now I can explain the similarity.
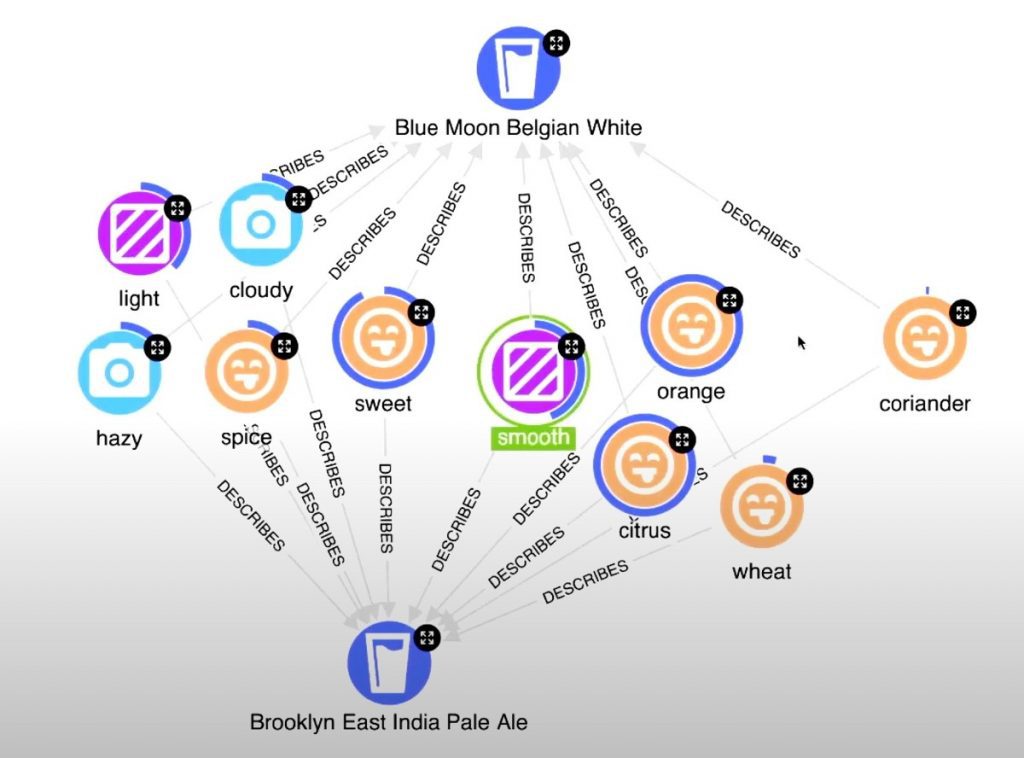
What this query is doing is running that same parameterized dimensional analysis through the beer graph, but it’s doing it specifically at the intersection of these two beers and computing the intersection of their different named entities. So we can see in the results that we have our Blue Moon Belgian White and we have our Brooklyn East India Pale Ale, and we have the different pieces of flavor, appearance, and texture that intersect between these two beers. Then the donut represents the score of basically the multiple of how strong these terms correlate to a Blue Moon Belgian White and a Brooklyn East India Pale Ale.
We can see that coriander, which is a very famous flavor in the Blue Moon Belgian White, has a very low correlation, so obviously the Brooklyn East India Pale Ale doesn’t share that strongly. But they both very strongly share flavors of orange and citrus, as well as being sweet, smooth, light beers that are potentially slightly cloudy or slightly hazy. This really explains how we’ve gotten to this Brooklyn East India Pale Ale and why someone who enjoys Blue Moon Belgian White might enjoy this IPA.
Which gets us to a number of different value propositions here. One is that we’ve taken our domain expertise of understanding that flavor, texture, and appearance are key drivers in making recommendations, and we’ve still managed to come up with an unexpected recommendation which is explainable. So we’re making new, interesting recommendations to our users and we’re able to explain that, which is especially powerful in a consumer use case, as well as a number of other similarity clustering use cases. But being able to recommend to our users
[00:20:00] that they enjoy a Brooklyn East India Pale Ale because it has a similar orange and citrus and sweet flavor to a Blue Moon is an incredibly nuanced way to make recommendations and justify that knowledge to our consumers.
But maybe we want to take this a step further, as we mentioned, and we want to start looking at some of the other data science algorithms that are available out there to us through Neo4j.
We might want to shift into looking at our cosine similarity, because as we look at our reviews – which I’ll cover in a moment – our reviews actually have different scores for appearance, flavor, and texture, and we can combine those into a vector and compute the cosine similarity between those vectors. We like to call this a “Beer Walk.” We’re going to start with a beer again, and then we can use our cosine similarity to essentially walk out from there, finding a next similar beer along the path.
We can find similar beers based on that pattern of review scoring, and it can also be paired with our parameterized dimensional recommendation, our Cold Start problem or Cold Start solution, to make recommendations as well. As we said, we can combine these in different modules and we can explore through our universe of beers and beer graphs, and pick the best matches while maintaining that diversity. So we don’t end up always aggregating back to a central point, but we can make incredibly diverse recommendations.
If I come back into Hume here, we can go back to our schema, and if I open up a number of our reviews, you can see – I’ve got review grouping turned on here, which is one of our visualization features. I’ll disable that for our demo. If I zoom in to Review and click on it, we can actually see that we have our review attributes here, and I can open the detail to look at it a little bit more clearly.
We can see the different properties within our review, and we have, as I mentioned, different scores for appearance, taste, and palate. Palate is texture. So we can actually leverage these scores into a vector. I’ll bring up my Blue Moon Belgian White again on my screen to make a different recommendation. We can actually click on this action, and we’ll see that we have a Beer Walk. This is going to run that graph data science cosine similarity algorithm, computing vectors of scores between all the reviews of the Blue Moon Belgian White and different beers in our beer graph.
We can see that we’ve actually made quite a jump here. There is some randomness associated because the vectors in beer graphs often are similar, so we do take a random beer from our results of similar reviews. But we’ve recommended a Saint Barb’s Tripel from our Blue Moon Belgian White, which is definitely a new, diverse recommendation. And we can continue taking this Beer Walk, exploring our cosine similarities, to explore throughout our beer graph, throughout our universe of beers. We’ll continue to compute that cosine similarity and make new, diverse recommendations with our little bit of randomness introduced into the system.
Then lastly, what I really want to cover is how flexible beer graphs are. One of the things that we talk about in some of our presentations is that when you’re creating a traditional relationship diagram or a traditional schema in a traditional database, you need to solve all of the problems at the beginning because it requires incredibly esoteric sets of rules to make sure that everything works and that you don’t have incredible query cost by having to make traversals across joins. In a graph, you don’t have that problem. So your schema can be very flexible and evolve over time.
Let’s say we start out with this dataset where we’re just a website making recommendations to people based on beer reviews, and then we see a business opportunity and we want to explore and to expand into actually selling beers. We want to now only make recommendations of beers that we have in inventory, so I can come in here, into my properties, and add Inventory as a property of my beer node. I can leverage that in my query to only recommend beers that have an inventory greater than zero in the beer graph.
But maybe we want to take that a step farther. Now we have a number of product pages where people are exploring beers, and they’re traversing from one page to the next, and we want to include some of that website data in our recommendations. So we can introduce a new node of website page, and the beer might exist on that page, and the user may visit that website page.
Now between our beers, we have another path, between users and website page, and between our users, we have an additional path of website page. We can actually see quite easily that this is another dimension that we can introduce to our recommendations. We can do the same thing by adding another dimension, potentially of social post, and adding the same
[00:25:00] relationships in there. In this way, we can expand our graph easily to include new, nuanced dimensions for our recommendations without having to do a complete redesign, without having to spend six months working on a project just to translate our schema into our new design. It’s all incredibly flexible and easy to add and leverage into our graph, so we don’t have to solve all of the same problems at the beginning; we can have our schema grow with our business use in order to make better recommendations and find better similarity.
And with that, I’ll turn it back over to Joe.
Joe O’Donnell: Great, thank you very much, Will. I don’t know about everyone else, but I now have a craving to go out and get myself a beer and a hot dog. But before I do that, I did want to get to some of the questions that we did have in the chat channel. I want to thank everyone for providing those questions.
Will, the first one I think would be targeted towards you. There was a question about “How would you know if the dimensional approach is working better than a collaborative filter?”
Will Evans: Yeah, absolutely. One of the things that we want to look at is basically just seeing that for a typical collaborative filter or typical tree-based model, you’re looking at a combination of regressive preferences of users together and finding some similarity that may be that bias in the system already. Whereas by looking at this dimensional system, we’re able to expand out throughout a much broader set of beers within our beer graph database or within our universe of beers to make more nuanced and diverse recommendations to users rather than just aggregating around existing bias or existing user clustering within the system.
Joe O’Donnell: Great, thank you, Will. Let’s see, another question is: “What are some of the other common graph use cases, other than a recommendation engine?” I’ll take a stab at that, and then Will, please do chime in as well.
There are a number of different use cases for graph database and graph data science. What we’ve seen when you take a look at the hundreds of customers that we have, most of them fall into five specific categories. One is around fraud detection and analysis; second one is around network and IT operations; third one is around research and development; fourth one is around master data management; and then fifth, quite prevalent, is the one that we’re doing today: real-time recommendations.
Will, do you have anything to add to that?
Will Evans: I think you’ve really covered it. We do a lot of work in the finance space, in regulatory compliance. As you mentioned, we do a lot of work in research, especially with NLP and the power of graphs to leverage NLP to make those highly dimensional recommendations. So a lot in pharmacology, science, and research in terms of predicting technology trends based on previous research. Those are definitely some big use cases for us as well.
Joe O’Donnell: I think we have time for just a couple more questions. Again, Will, this one is more for you. “Why is this a better alternative to bootstrapping with synthetic data to make up for the sparseness?”
Will Evans: Yeah, absolutely. That’s really something that we see customers trying to do pretty frequently. One of the things that we find is an issue with bootstrapping is that you have to find a way to control the level of randomness in your data so that you’re not introducing bias. Then you end up in this iterative cycle of “Is my data too random and I’m not getting results? Or in my randomness, am I introducing too much bias and my recommendations are just based on that bias?” It’s hard to tell what’s coming from real data versus this tunable parameter of randomness in my bootstrapping.
If we instead leverage the graph, we’re only leveraging our real data. We’re only looking at the dimensions that we have existing to us, and we can actually increase those. But it’s based on the actual data, not on a parameter that we’re tuning in some model. So we can actually not introduce as much bias
[00:30:00] into our recommendations while not needing to create these large datasets of averages with bootstrapping.
Joe O’Donnell: Great, thank you. Thank you, Will. Lastly, someone did take us up on the question that’s on the page right now, asking about the free software trial and consultation to get you started.
Graph database has been around for a while, but we realize that it’s, for a lot of companies, a relatively new technology to embrace. What has made our customers successful – and when I say our, I’m talking both Graphable and Neo4j – how we’ve helped them succeed is really rolling up our sleeves and getting into the boat and rowing with them. So when we talk about providing a free software trial and consultation to get you started, we’re talking about setting up the parameters for a successful project, one that would provide immediate value for you as well as momentum in leveraging graph technology for business cases in your organization.
If you reach out to Will and/or I about that, we can discuss the parameters of what that engagement would look like.
Lastly, when we talk about adopting graph (and possibly beer graphs) in your organization, there’s plenty of places for you to get started, not just picking up the phone and calling Will and I. We will send out the beer graph slides, which will include links to these various resources, and if you have any additional questions or want additional information, please don’t hesitate to reach out to Will and I.
At this point in time, I want to thank everyone for joining the webinar and exploring the world of beer graphs with us. Hopefully you’ve found this as useful and as interesting as we have, and we look forward to engaging with you in the future. Happy Cinco de Mayo. Goodbye.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success.Contact usto learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.