CONTACT US
Graph Database vs Relational Database – Similarities & Differences, Explained

How is graph database vs relational database (classic RDBMS) the same and how are they different? As always in tech, it depends. While an easy rule-of-thumb is that you should deploy a graph database in use cases that are focused more on the value of the connections inside the data as opposed to simply the data itself, in this article we will explore the similarities and differences between these two types of databases, as well as offer common use cases where graph database is obviously a better fit.
Graph Database vs Relational Database – Overview
Probably the best way to start is to illustrate the differences with a common use case for graph databases- assembling a 360 degree view of an entity- in this example below, showing an employee. With related and important data often being stored across many different systems, this can often be a real challenge for relational databases, particularly at enterprise scale. In the diagram below you can see the overall difference in what it takes a graph database vs relational database to assemble and process the same information.
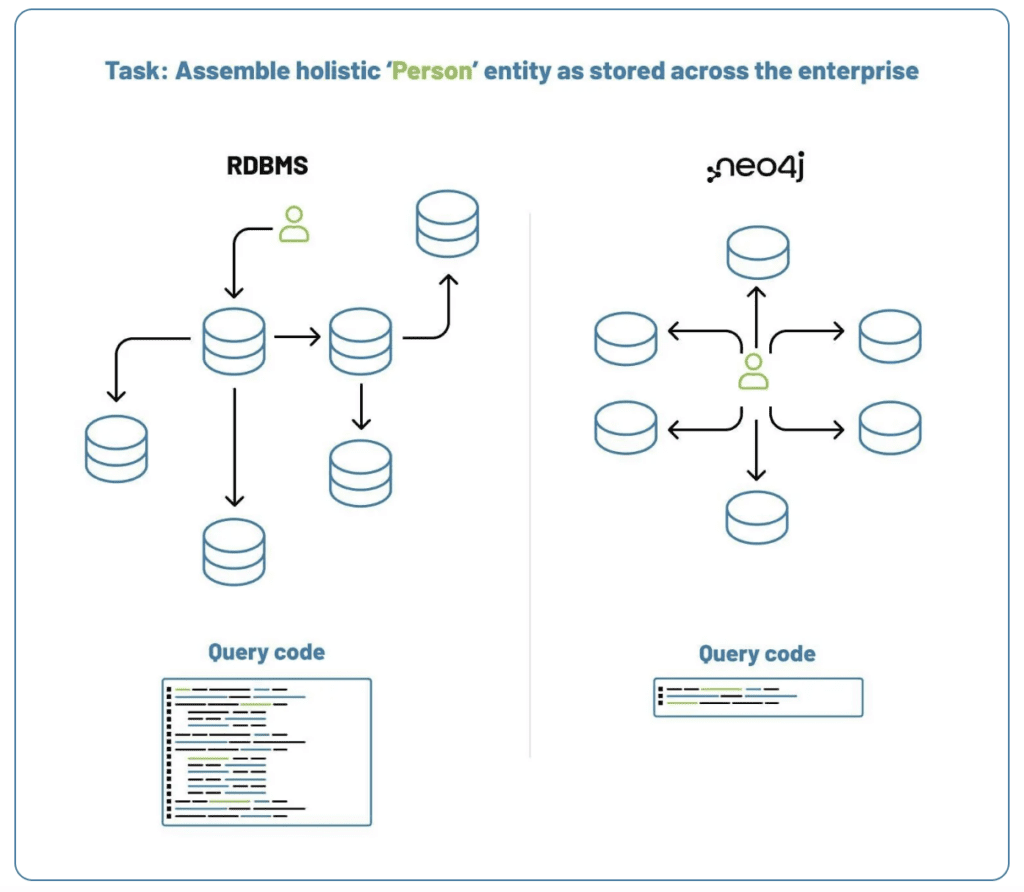
The above may be enough to give you a sense of the differences if you are just looking at the highest level. Here are some resources to go a bit deeper on graph database in particular: What is a Graph Database? / What is Neo4j (Graph Database) and graph database use cases.
Graph vs Relational Database – Considerations
In an evaluation, you may at least take into consideration the following aspects of an implementation that might impact this decision, to determine the optimal database for your use case. It is beyond the scope of this article to discuss every single decision criteria, but know that any of these has some potential to influence your decision.
- source and required target data structures
- access to source systems and databases
- relationship of the core data to other data both in and outside the org,
- method of data usage, storage and retrieval,
- adopted design patterns (e.g. CQRS),
- industry-standard(s) utilized
- adopted design-orientation (e.g. data-driven design, domain-driven design),
- architectural approaches (e.g. layered architecture, event-driven architecture, microservices architecture), and
- programming paradigm in use (e.g. reactive programming etc)
Next we will explain common similarities and differences in these two very distinct Data Base Management Systems (DBMS) and how some of these above can come into play as you decide.
Quick Overview of Centralized vs Distributed Systems
An application rarely stands on its own. We usually integrate it into some kind of larger system- either application-driven or network-driven- and the similarities of the relational vs graph database can be seen through this lens, so it will be important to first describe what we mean to begin.
Centralized System
Directed by the application in a centralized system, both relational and graph databases can be ACID-compliant, they can provide high availability through replication and failover to mitigate single points of failure, while still supporting flexible queries.
Distributed System
Directed by the network in a distributed system (which networks weren’t initially designed for), it is more difficult for relational and graph databases to run efficiently. We’re not saying that they’ve not improved or are not evolving- they have and continue to improve. (More details about Neo4j architecture can be found here: Neo4j Performance Architecture.)
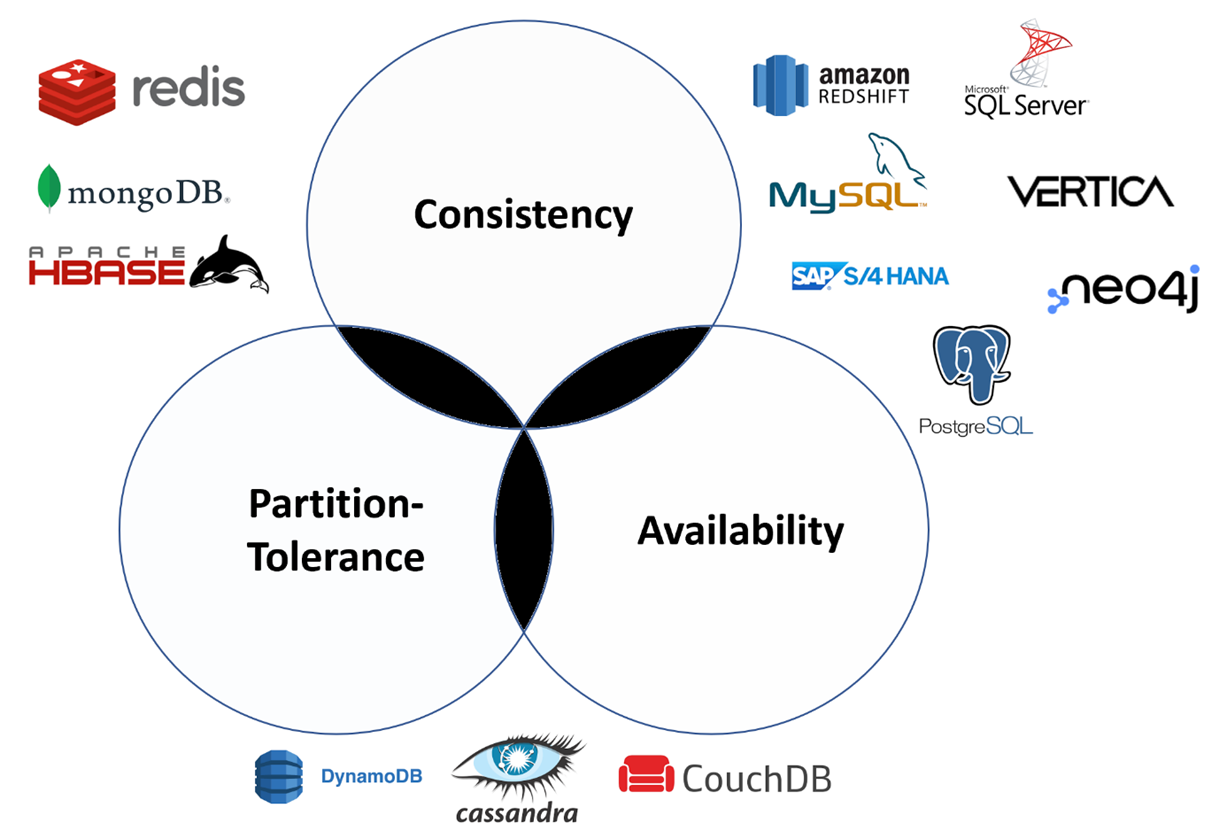
It is however worth underscoring that we suggest using the CAP Theorem (The theorem states that any distributed data store can provide only 2 of the following 3 guarantees: Consistency, Availability and Partition Tolerance) to discuss how to evaluate network-driven application architecture.
In this context, by default applications suffer from network partition, where parts of the graph database exist across subnets. So, unlike the desired Iron Triangle in project management, we instead must pick only one of two options: consistency or availability, since partition tolerance is essentially mandatory. Usually the standard is to pick availability, and instead trade consistency (data is the same across the cluster, so you can read or write from/to any node and get the same data) for partition tolerance (the cluster continues to function even if there is a “partition” or communication break between two nodes).
Obviously that is not ideal and it is why companies and architects are constantly having to evaluate the significant availability and performance benefits of distributed systems vs centralized systems.
Relational vs Graph Database – Similarities
The leading solutions in this area share many similar concepts. The best way to understand the similarities is by comparing the essence of the two differing sets of terms describing graph database vs relational database- that can mean essentially the same thing,
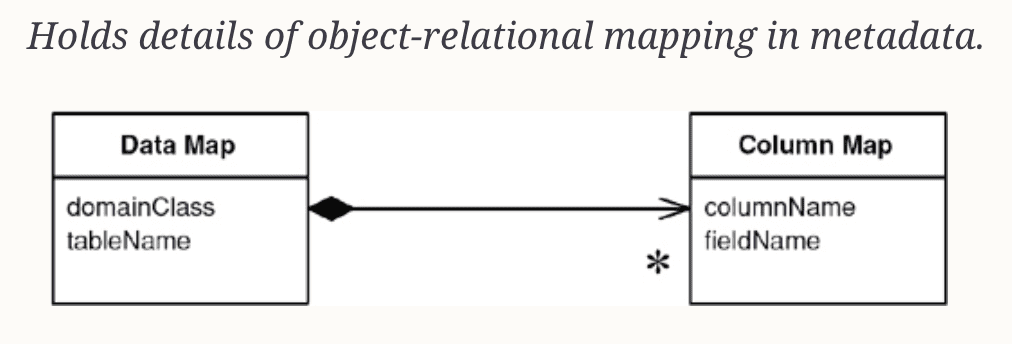
For example, in the graph database world, we could think of a node label as a kind of table structure, a relationship as a kind of associative table, and a node instance as a kind of row. For even more depth, Neo4j compares these two data store models in greater detail here: Organizational Data Domain. As such, we can rely on common data access patterns (e.g., Metadata Mapping Pattern) for the ORM in both cases. As a result we can also use increasing levels of abstraction to better enforce consistency in our application.
A dominant design approach today is Domain-Driven Design (DDD). Using DDD, the application uses the domain model as the core driver for database design. We’ll can use DDD as a means to explain the functional similarities between these two DBMSs from the perspective of the internal application as explained below.
Functional similarity: The Access Model / INternal Application
In practical use, the differences may not be that great or apparent between graph database vs relational database. For example, the Object-Relational Mapping (ORM) is very similar and often even the code we implement using ORM can be quite similar. To illustrate, below we show side-by-side code examples of how to implements a domain class with Java Spring to minimize the code required. This also emphasizes the use of established conventions, by showing an approach called convention-over-configuration.
Relational Database Example (using a JPA-compliant databases such as MariaDB, Oracle etc)
import ...
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
@Entity
@Data
@NoArgsConstructor
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class Coffee {
@Id
@GeneratedValue
private Long id;
private String type, category, quantity;
@JsonProperty("brewing_time")
private int brewingTime;
@JsonProperty("brewing_temperature")
private int brewingTemperature;
}
Graph Database Example (e.g. Neo4j)
import ...
import org.springframework.data.neo4j.core.schema.GeneratedValue;
import org.springframework.data.neo4j.core.schema.Id;
import org.springframework.data.neo4j.core.schema.Node;
@Node
@Data
@NoArgsConstructor
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class Coffee {
@Id
@GeneratedValue
private Long neoId;
private Long id;
private String type, category, quantity;
@JsonProperty("brewing_time")
private int brewingTime;
@JsonProperty("brewing_temperature")
private int brewingTemperature;
}
Those examples are abbreviated in code and scope to illustrate the similarities in the ORM, showing the functional similarity of the two types of databases. Additionally we also see the common domain class. And while there are some minor syntax differences between the two examples, we end up with entities ready to be handled exactly the same.
Technical Similarity #1: In practical implementation terms, partition tolerance is the ability to partition your system through sharding and to be able to tear down any inconsistent node until the system resolves it.
Partitioning a traditional relational database context is considered to be in the category of “unnatural acts“[8]. Even if one could argue this is feasible via application layers, virtual sharding still remains an ad-hoc solution at best in the relational world.
A significant similarity is that the same actually applies to partitioning a graph database. For a variety of reasons, sharding is difficult and traversing a distributed graph always impairs performance.
Technical Similarity #2: Another similarity is neither relational nor graph databases exhibit availability attributes. Assuming both are eventually consistent (see below) and that both have relationships spawning between partitions, they will eventually corrupt the data.
"Discussing atomic consistency is somewhat different than talking about an ACID database, as database consistency refers to transactions, while atomic consistency refers only to a property of a single request/response operation sequence. And it has a different meaning than the Atomic in ACID, as it subsumes the database notions of both Atomic and Consistent."[10]
Technical Similarity #3: Another similarity relates to the distributed query engines, where both options typically provide data federation. That being said, at present, graph databases only provide data virtualization by reusing SQL-based distributed engines.
The above all represent some of the technical and functional similarities of a graph vs relational database models, now lets look at the differences.
Relational vs Graph Database: Differences
We may choose one DBMS type or string different ones together in one system. Regardless, we would certainly want to take advantage of their unique strengths.
Centralized System
Because of the schemaless nature of graph database (or a better term would be “schema optional”), one of graph databases’ main advantages over relational is it’s suitability to query a data network, particularly on the reads.
Relational data stores can also query over a network by implementing relationships using foreign keys, optimizing queries through materialized views, triggers, indexes, and more. Relational databases offer flexible read and write workloads, and excel over graph databases in performance when writing to the database.
The real difference in ability emerges around highly connected data. Having to use SQL joins can significantly impair reading performance, particularly at scale and across systems. There is what is called and impedance mismatch, where the nature of SQL is not a natural fit at all times for querying highly connected data.
As with all technology, we can do technical acrobatics to work around the existing data model. When we do so, it usually has a cost in terms of query performance as abstraction increases. The need for efficiency eventually forces us to either keep evolving the schema or the friction and inefficiency often compels us to put in place a migration strategy to something more suitable like a graph database.
Distributed System
Now, in a distributed system, graph databases require strong consistency. Yet, in order to scale, we ultimately have to relax our consistency requirements (see CAP Theorem above) which immediately introduces architectural tension and difficult decisions around resulting loss of fidelity. Because of this, graph vendors have introduced new ways of dealing with this reality. For example, Neo4j introduced causal consistency (to maintain its state across replicas, even when communications may be interrupted).
On the other hand, as we discussed previously, because traditional relational databases have not been able to perform efficiently in a distributed environment, in response a new kind of relational database has emerged: distributed SQL (e.g. MariaDB). This approach adapts to different distributed workloads more easily and as a core value prop, attempts to deal with the loss of fidelity by graph/NoSQL databases in consistency and data integrity at scale.
As a last difference in a distributed context, new distributed SQL databases are able to more naturally accomodate distributed queries across a distributed system, while historically graph databases have had more difficulty supporting it. For example, Neo4j had mnot been able to traverse a graph across multiple shards, but later came up with a workaround to simulate sharding through data federation and so is able to query each database as distinct databases.
Optimal Use Cases for Graph Database vs Relational Database
Examples of best-fit use cases include but are not limited to:
Relational Database
- Certain ERP applications (where highly normalized data may be imperitive)
- OLTP (Online Transactional Processing)
- Data Warehousing
- BI Reporting
- Intensive Writes
Graph Database
- Connected Data used cases in general
- HTAP (Hybrid Transactional and Analytical Processing)
- Location-based Services
- Recommendation Engines
- Near-Real-Time Analytics
- Intensive Reads
- Fraud analytics
- Identity & Access Management
- Knowledge Graphs
- Master Data Management
- Apps around Large Language Models / LLMs
Reference List
- Graph Database
- Convention-over-configuration
- Organizational Data Domain
- Metadata Mapping Pattern
- Neo4j Performance Architecture
- Data Federation
- Data Virtualization
- Sadalage-Fowler. NoSQL Distilled. 2012
- Iron Triangle
- Gilbert-Lynch. Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services. 2002
- Distributed SQL
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: