CONTACT US
What is Data Lineage and Data Provenance? Quick Overview

The question of what is data lineage (often incorrectly called data provenance)- whether it be for compliance, debugging or development- and why it is important has come to the fore more each year as data volumes continue to grow. Read on to understand data lineage and its importance.
What is Data Lineage?
The best data lineage definition is that it includes every aspect of the lifecycle of the data itself including where/how it originates, what changes it undergoes, and where it moves over time. While simple in concept, particularly at today’s enterprise data volumes, it is not trivial to execute. However difficult it may be, the fruits are important and now even critical since organizations are relying on their data more and more just to function and stay in compliance, and often even to differentiate themselves in their spaces.
What is Data Provenance? How is it Different from Data Lineage?
There is definitely a lot of confusion on this point, and the distinctions made between what is data lineage and data provenance are subtle since they both cover the data from source to use. That being said, data provenance tends to be more high-level, documenting at the system level, often for business users so they can understand roughly where the data comes from, while data lineage is concerned with all the details of data preparation, cleansing, transformation- even down to the data element level in many cases. The below figure shows a good example of the more high-level perspective typically pursued with data provenance:
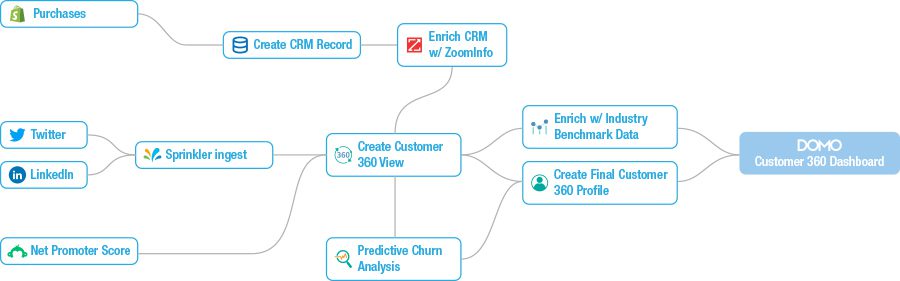
Why is Data Lineage Important?
As a way to think about it, it is important to envision the sheer size of data today and its component parts, particularly in the context of the largest organizations that are now operating with petabytes of data (thousands of terabytes) across countries/languages and systems, around the globe. To give a few real-life examples of the challenge, here are some reasonable questions that can be asked over time that require reliable data lineage:
- What if a development team needs to create a new mission-critical application that pulls data from 10 other systems, some in different countries, and all the data must be from the official sources of record for the company, with latency of no more than a day?
- Or what if a developer was tasked to debug a CXO report that is showing different results than a certain group originally reported?
- And as a worst case scenario, what if results reported to the SEC for a US public company were later found to be reported on a source that was a point-in-time copy of the source-of-record instead of the original, and was missing key information? How could an audit be conducted reliably?
Unfortunately, many times the answer to these real-life questions and scenarios is that people just have to do their best to operate in environments where much is left to guesswork as opposed to precise execution and understandings. The impact to businesses by operating on incorrect or partially correct data, making decisions on that same data or managing massive post-mortem discovery audit processes and regulatory fines are the consequences of not pursuing data lineage well and comprehensively.
How does Data Lineage Work?
More often than not today, data lineage is represented visually using some form of entity (dot, rectangle, node etc) and connecting lines. The entity represents either a data point, a collection of data elements, or even a data source (depending on the level currently being viewed), while the lines represent the flows and even transformations the data elements undergo as they are prepared for use across the organization. See the figure below showing an example of data lineage:
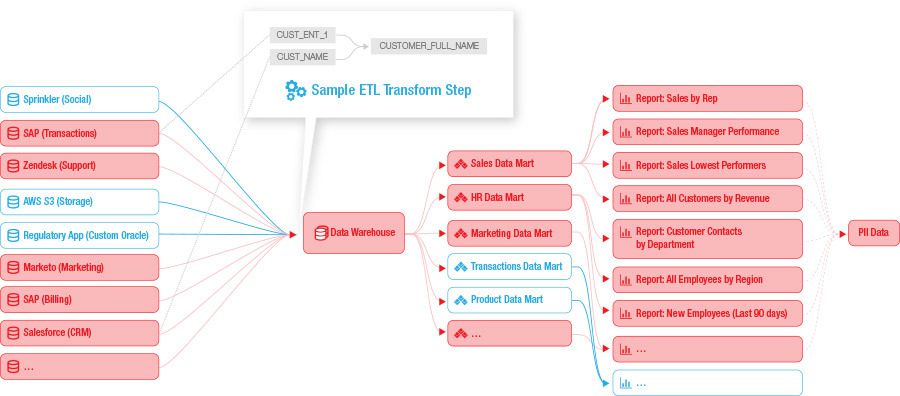
Typically each entity is also enabled for drilling, for example to uncover the sample ETL transform shown above, in order to get to the data element level. Very often data lineage initiatives look to surface details on the exact nature and even the transform code embedded in each of the transformations. In this way, impacted parties can navigate to the area or elements of the data lineage that they need to manage or use to obtain clarity and a precise understanding.
There is both a horizontal data lineage (as shown above, the path that data traverses from where it originates, flowing right through to its various points of usage) and vertical data lineage (the links of this data ‘vertically’ across conceptual, logical and physical data models).
This construct in the figure above immediately makes one think of nodes/edges found in the graph world, and it is why graph is uniquely suited for enterprise data lineage and data provenance (find out more about graph by reading “What is a graph database?“). Read more about why graph is so well suited for data lineage in our related article, “Graph Data Lineage for Financial Services: Avoiding Disaster“.
Also, a common native graph database option is Neo4j (check out Neo4j resources) and the most effective way to manage Neo4j projects work is with the Hume platform (check out and Hume resources here). An association graph is the most common use for graph databases in data lineage use cases, but there are many other opportunities as well, some described below.
The Unique Challenges of Data Lineage
The challenges for data lineage exist in scope and associated scale. It’s easy to imagine for a large enterprise that mapping lineage for every data point and every transformation across every petabyte is perhaps impossible, and as with all things in technology, it comes down to choices. Very typically the scope of the data lineage is determined by that which is deemed important in the organization’s data governance and data management initiatives, ultimately being decided based on realities such as development needs and/or regulatory compliance, application development, and ongoing prioritization through cost-benefit analyses.
Documenting Data Lineage: Automatic vs Manual
The question of how to document all of the lineages across the data is an important one. There are data lineage tools out there for automated ingestion of data (e.g. SAS, Informatica etc), and other tools for helping to manage the manual input and tracking of lineage data (e.g. data lineage tools like Collibra, Talend etc), and there are pros and cons for each approach. Realistically, each one is suited for different contexts.
For example, for the easier to digest and understand physical elements and transformations, often an automated approach can be a good solution, though not without its challenges. Conversely, for documenting the conceptual and logical models, it is often much harder to use automated tools, and a manual approach can be more effective. These decisions also depend on the data lineage initiative purpose (e.g. regulatory, IT decision-making etc) and audience (e.g. IT professionals, regulators, business users etc).
What is Data Lineage: Conclusion
There is so much more that can be said about the question What is a Data Lineage? particularly when digging into the details of data provenance and data lineage implementations at scale, as well as the many aspects of how it will be used. This article set out to explain what it is, its importance today, and the basics of how it works, as well as to open the question of why graph databases are uniquely suited as the data store for data lineage, data provenance and related analytics projects. For even more details, check out this more in-depth wikipedia article on data lineage and data provenance.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: