CONTACT US
Agile Data Science is One Way to Fail

Most tech leaders and developers would agree that the Agile methodology that began to dominate the software development world in the early 2000’s was a significant step forward. But an important question to ask is if it is an appropriate fit for every kind of software-related project, especially in the case of Agile data science.
Agile Data Science vs Agile Development
Agile delivery in software development relies on collaboration between cross-functional teams. With an emphasis on adaptive planning that is flexible to change, the goal of Agile is to ensure early delivery of working software that then moves into a process of continuous improvement. Within this framework, Agile developers seek to build products instead of simply completing projects, with a view to introduce capabilities and solutions into the product incrementally. But, there have always been questions as to whether agile methodologies are a good match for data science-related development. But the Agile methodology in the context of data science has proven to be much more of a challenge, for a variety of reasons. Using a biological lens instead of the traditional computing and mathematical perspectives, we will look at why.
With the COVID-19 pandemic, we have all been converted into armchair biologists and this presents a good opportunity to see if lessons from biology can be applied to the current context of building successful data science programs. By taking a deeper look at the distinction between maturation and evolution (terms that are incorrectly used interchangeably in Agile), we hope to shed some new light and offer new perspectives on engineering processes as they relate more specifically to data science and how that impacts the use of Agile data science.
Crawl-Walk-Run: Evolution or Maturation?
From a biological perspective, many of the concepts used in Agile are fairly incongruent. The most common is the concept of a crawl-walk-run approach as a core tenet of Agile, with people often linking that imagery to a process similar to evolution.
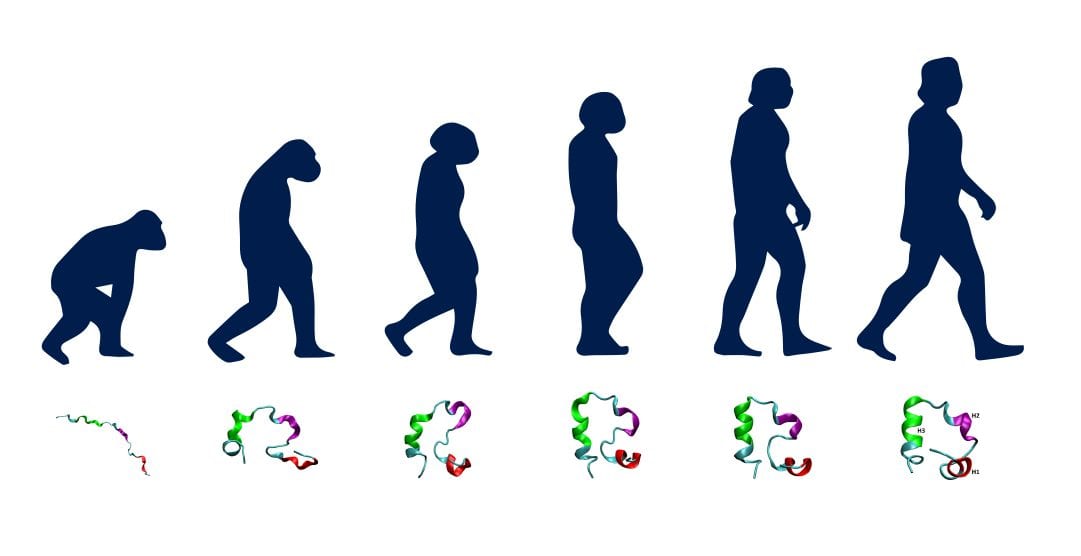 But the transition from crawl to walk to run would actually be better characterized as a maturation process which differs drastically from the theory of evolution. In the case of maturation, the entity itself is still the same as it matures, but it is going through a change process. These maturing changes in turn allow the transition from crawling to walking to running to happen. An example of this could be a software platform maturing over time version by version, not really the case even using in agile data science.
But the transition from crawl to walk to run would actually be better characterized as a maturation process which differs drastically from the theory of evolution. In the case of maturation, the entity itself is still the same as it matures, but it is going through a change process. These maturing changes in turn allow the transition from crawling to walking to running to happen. An example of this could be a software platform maturing over time version by version, not really the case even using in agile data science.
As another example, in the analytics world, many of us are used to seeing the analytics maturation process that typically moves from descriptive to diagnostic, to predictive and then to prescriptive analytics. This clearly illustrates a process that has added capabilities over time. Oftentimes people believe incorrectly that data science projects should follow this same maturation approach, with each iteration involving increasing computing power and building new mathematical models at each phase in the process- unfortunately the reality is quite different in agile data science.
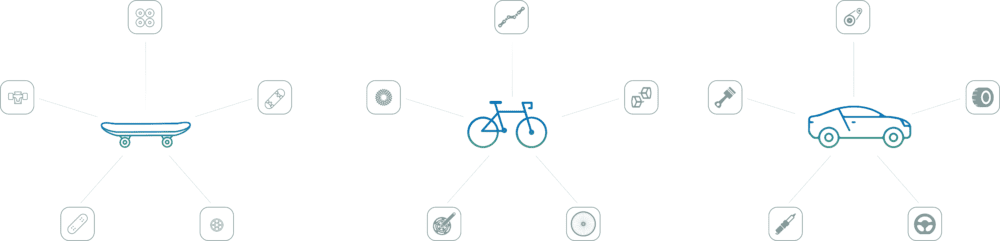
Does Transforming a Skateboard into a Bicycle Count as Evolution?
More imagery that we often see in Agile is that of progressing from a skateboard to a bicycle and then to a car and so on as way of describing the change over time. In fact, this should be called a process of improvement or maturation towards ease and comfort as a goal, building a vehicle that becomes easier to ride and steer and that also has increasing levels of automation. Within Agile, product owners often connect this imagery incorrectly to evolution. Evolution is simply not a goal-driven process of adding capabilities or making purposeful physical changes.
As an example from evolution, if we look at the case of a very brightly colored poisonous frog, becoming brightly colored or poisonous is not a goal or an intentional path within evolution. When the first generation of frogs become toxic to their predators, they all still get eaten, and the only result is that it kills the predator. In reality, these colorful markings in combination with being poisonous are only beneficial once enough of the predators have died and the predators have eventually somehow learned to stay away as a survival tactic that has been passed on through generations. In this example, as with data science, not every step is a purposeful move in a specific direction.
Now, to make things even more complicated, the evolution that makes a colorful, poisonous animal is actually the result of many tiny adaptations to the genetic sequence over a long period, with certain “jumps” that seem to advance species in wholly new ways. This process-by-selection is antithetical to the tenets of Agile that were meant to increase the speed of development by not having to build for a long time, to avoid creating an entire product before releasing it. In application development, no one could ever conceive of making many small independent changes to a code base while seeking a favorable outcome, the types of change one could find in evolution. Meanwhile, in data science this is part of the development reality, making Agile data science a bad fit. The Agile process starts with a very clear goal in mind and then specifically iterates toward that goal- very different from an evolutionary process.
How is this Relevant to Agile Data Science?
There is a tendency in the industry to treat data science and computer science as one and the same. Because of this, there is a misconception that the same rules that govern the process of application development can be applied to data science projects and products. As stated above, application development involves a maturation process where we consistently add new features that are built on the prior state, but with the same essential purpose and outcome. For example, no one expects the addition of a new toolbar in the user interface to cause a web application page to have a completely different purpose, which could be considered expected in an evolutionary process and also in data science development.
With data science however, projects can be built on many modular components where the whole is often greater than the sum of its parts. This is especially true when using the ensemble approach, where the combined output of many different models is being used to generate the final outcome. This means that many small changes to the code base, seemingly unrelated and independent, can cause large scale changes in the overall model. As different features of the model and the models themselves interact, the final outcome can sometimes be unpredictable, just like changes or “jumps” in the genetic code in the theory of evolution. This seems much less like maturation, and much more like evolution which illustrates how the Agile development process makes Agile data science not the best fit for data science development.
Skateboards do not Evolve into Bicycles
Actually following the skateboard-to-bicycle and similar approaches would actually require a wholesale change of all components and engineering processes to get from one state (e.g. skateboard) to the next (e.g. Bike). Unfortunately, the design for a good skateboard does not necessarily equate to being a template for building a good bicycle and so on. For a parallel example within data science, usually data science models built on a small data set as a pilot work fairly well, but the changes in data distribution when a large data set is used can completely derail the model. The analogy here is that a great skateboard that was an amazingly fun ride turned into a horrible bicycle and the entire project gets abandoned before it can become a car.
Redefining what is the Product
But what does it truly mean to build a working data science “product” if it is more rightly viewed as a constantly and often unexpectedly changing entity? Often, the product in Agile data science (and all data science) is incorrectly judged based on the accuracy of the output, instead of the utility and impact to the business. If one thinks instead about the data science product as an evolving entity, then we will view the product as actually being whatever significantly impacts and brings value to the business, given changing inputs (e.g. data).
While this makes defining what the actual product is a much more difficult and even changing process, it does tell us that tuning-metrics such as classification and prediction accuracy may not the best way to define a data science product and its value. Instead, data science products should take a business-centric view, instead using business performance metrics measured using dollars and cents or increased customer engagement as two examples, as the ultimate product. Most important is making sure that data science projects do not seem like an unending loop of tweaks to improve model accuracy with continuous trial-and-error. Instead, data science models should be optimized based on the soundness of mathematical principles alongside clear business acumen, not the error rate of the test-train process as an example.
Embrace the chaos
Because Agile data science is so ill-fitting for data science development, projects often end up using more of a traditional Waterfall methodology. But Waterfall isn’t a good fit either, because it takes far too long since everything is processed in series.
So, what is the answer? We need to embrace the chaos, implementing guidelines instead of the rigid rules found in those methodologies. While this could feel antithetical to everything you were taught in your computer science degree or your project management courses, it’s a reality if our goal is to drive business value and not to simply comply with process. So, if one had to name the methodology that begins to emerge in this discussion it could be what we have termed “Coding in Chaos”, the subject a future blog article. But in short, it means finding value in the process of constant change and iteration, even if the short-term outcome is unhelpful. It’s essentially experimenting your way to the emerging value that can truly impact the business. While it is beyond the scope of this article, we also recognize the value that the CRISP-DM methodology has brought to organizing data mining and data science projects. At the same time, we see a distinction in modern data science development where unlike the more systematic progression in CRISP-DM, in reality the arrows more often than not end up going in completely different and unexpected directions, and that is something we should expect, seek and leverage for the business.
Graph Databases for Increased Agility
So how does this discussion of Agile data science and the better-fit options out there connect back to the power of graph databases (e.g. Neo4j) and graph data science that we are so passionate about at Graphable? If the key to value-oriented data science development is “Coding in Chaos”, then the inherently flexible and schema-less nature of the graph-database maps uniquely well to what is required of iterative and experimentative data science development. When combined with the inherently cerebral structure of the graph database, which better represents both how the brain works as well as how the world around us is structured, it is no surprise that Google as a leader in data science has claimed that the foundation of the future of data science will be built on graph. We agree.
If you are evaluating whether or not an AI project will be a fit for your project needs, read about whether an AI consulting partner like Graphable is right for you to help evaluate and deliver your project.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: