CONTACT US
Graph ETL and Neo4j ETL Best Practices

Whether it be with Graph ETL or more specifically Neo4j ETL, like many efforts related to data engineering, loading data into a graph database and incorporating that data into your analyses can be accomplished in several ways. Find out how in this article, along with Graph ETL best practices.
What is Graph ETL / Neo4j ETL?
We are really talking about the same thing in both cases. Graph ETL speaks more generically to how you would accomplish this requirement, and Neo4j ETL is specifically looking at the nuances of ETL in that specific graph database.
What’s the Best Way to Ingest and Transform Data for Graph Databases?
As usual, there is not a ‘best’ way, but rather the right answer is often based on specific requirements, available resources, standard practices at your company, and your project’s objectives. In this blog post we are going to briefly survey various methods and then focus on using the graph insights platform GraphAware Hume for loading data into our graph database. During this journey, we will keep in mind our goal in this example is to perform clinical trial data analytics and demonstrate how our data ingestion pipeline can enable and accelerate this objective.
Getting Started: Neo4j ETL options
We will be loading our data into the graph database Neo4j. This database will store our data, enable the use of graph native algorithms which we will use in our clinical trial data analytics, and provide in-memory graph machine learning for future efforts with this same data.
The Neo4j database can be loaded and transformed using various software development toolkits (SDK), using Neo4j CLI tools, the Cypher language and stored procedures, and ETL platforms like Apache Hop, the Hume platform and Apache Airflow.
We are using Hume for this example because, in addition to having one of the most advanced graph-centric ETL capabilities, it is also a graph insights platform that can drive rapid time to value (TTV) in a project through its data management, analytics, and visualization capabilities.
Graph ETL for Clinical Trial Data in a Knowledge Graph
As the example graph database use case for this article, we are using clinical trial data that is identified as a component, or sub-graph, in a larger biotech knowledge graph shown below. The schema for the example project looks like this:
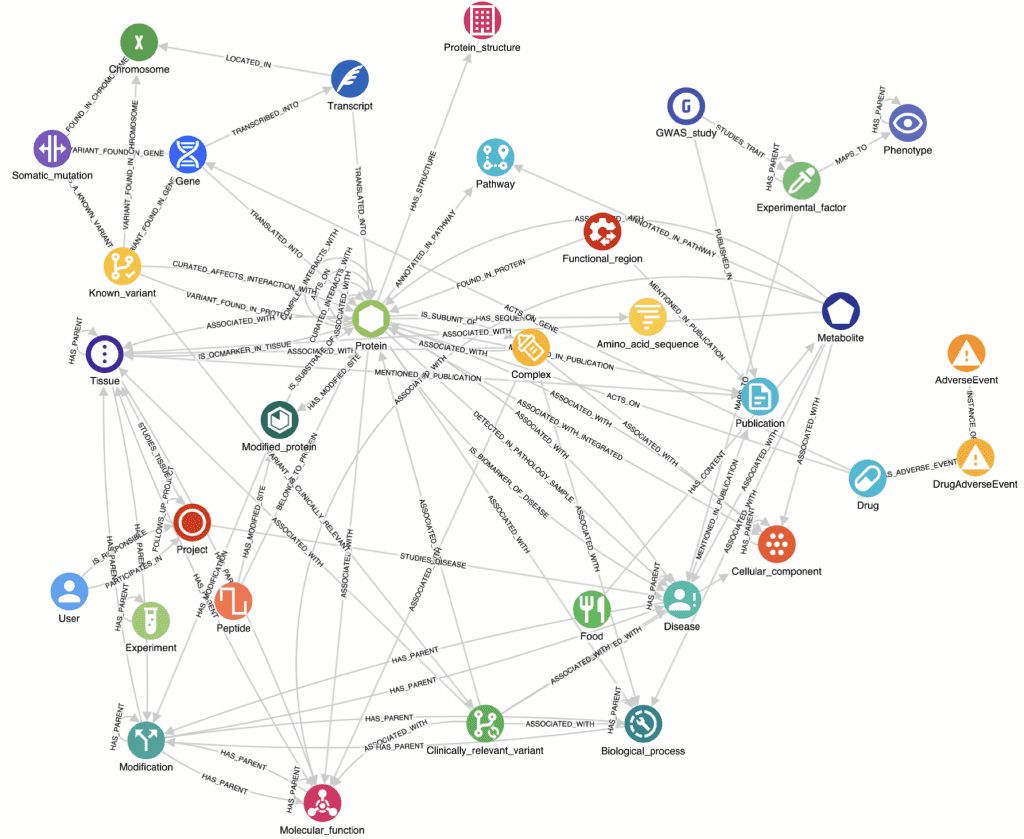
The above schema represents our project prior to integrating the clinical trial data. We will load the trial data sub-graph and link it to our larger graph using the trial’s interventional drug name and another data source’s drug node’s product_name property, as demonstrated below.
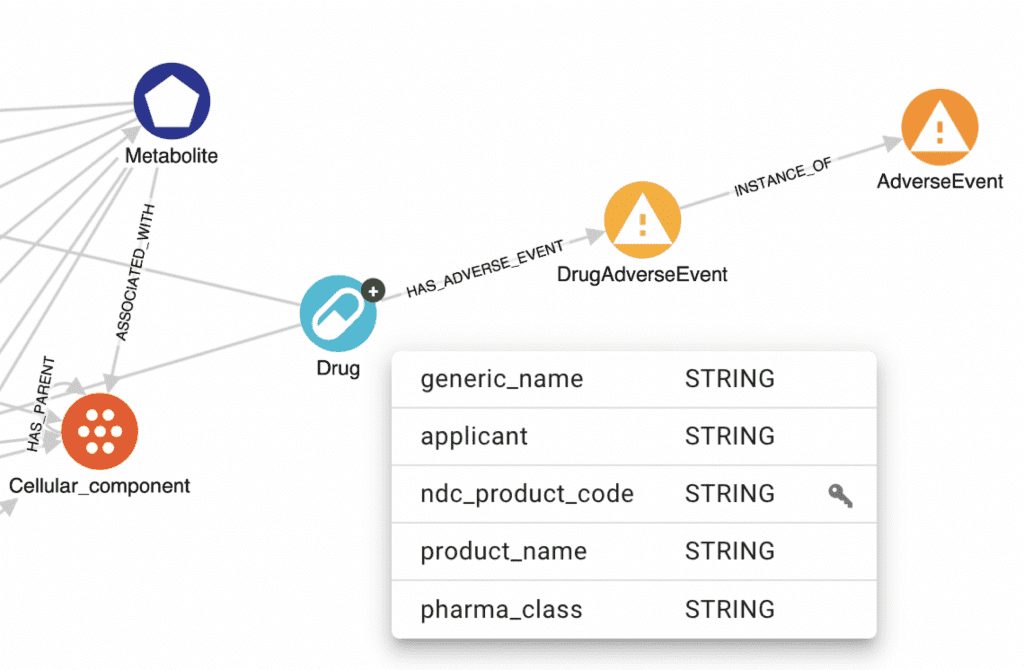
This ability to ingest data sources and link them together through semantic relationships is one of the many advantages of graph databases.
Neo4j ETL in Hume
To set up the example, we tested API calls to ClinicalTrials.gov and retrieved JSON results for ALS trials. Using the Hume platform we then create a visual ETL flow that starts with making the same API call and ends with all of our trial data loaded into the Neo4j database which is then ready for clinical trial data analytics using selected graph algorithms. Our finished pipeline looks like this:
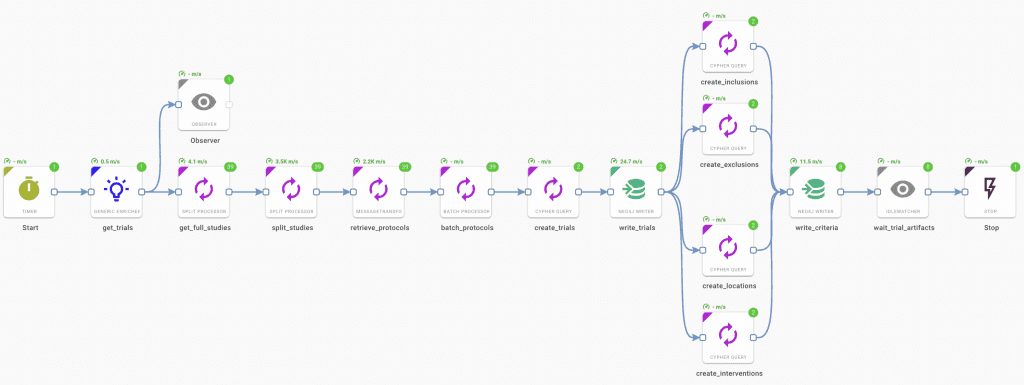
As mentioned above, the pipeline starts by making an API call to ClinicalTrials.gov, it then processes bulk messages in manageable batches, performs NLP operations, and then splits the returned results into batches for graph processing using Cypher. It finishes with writing our data as nodes with properties and linking nodes together using relationships. Each comment in the pipeline can be opened to view incoming data and configured for the desired output.
The pipeline utilizes an underlying schema to manage indexes and constraints to ensure data consistency and efficient loading.
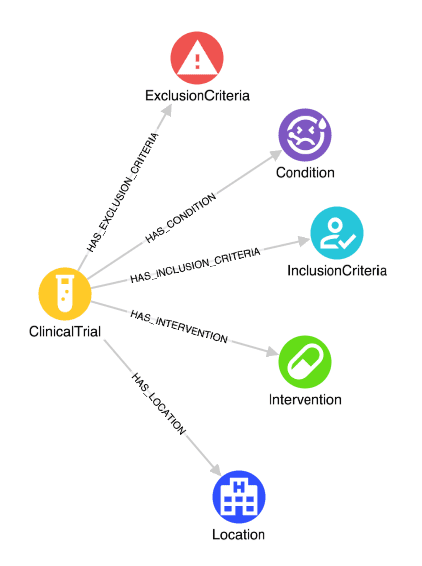
After the pipeline completes we can visualize our data in the Hume platform and also inspect a single clinical trial to validate our pipeline. Below we can see that an example trial conatins interventions (drugs), inclusion and exclusion criteria that demonstrate our NLP was executed successfully, and conditions are present. Actively recruiting trial locations are linked to the clinical trial which will include properties from our clinical trial data analytics efforts in upcoming steps.
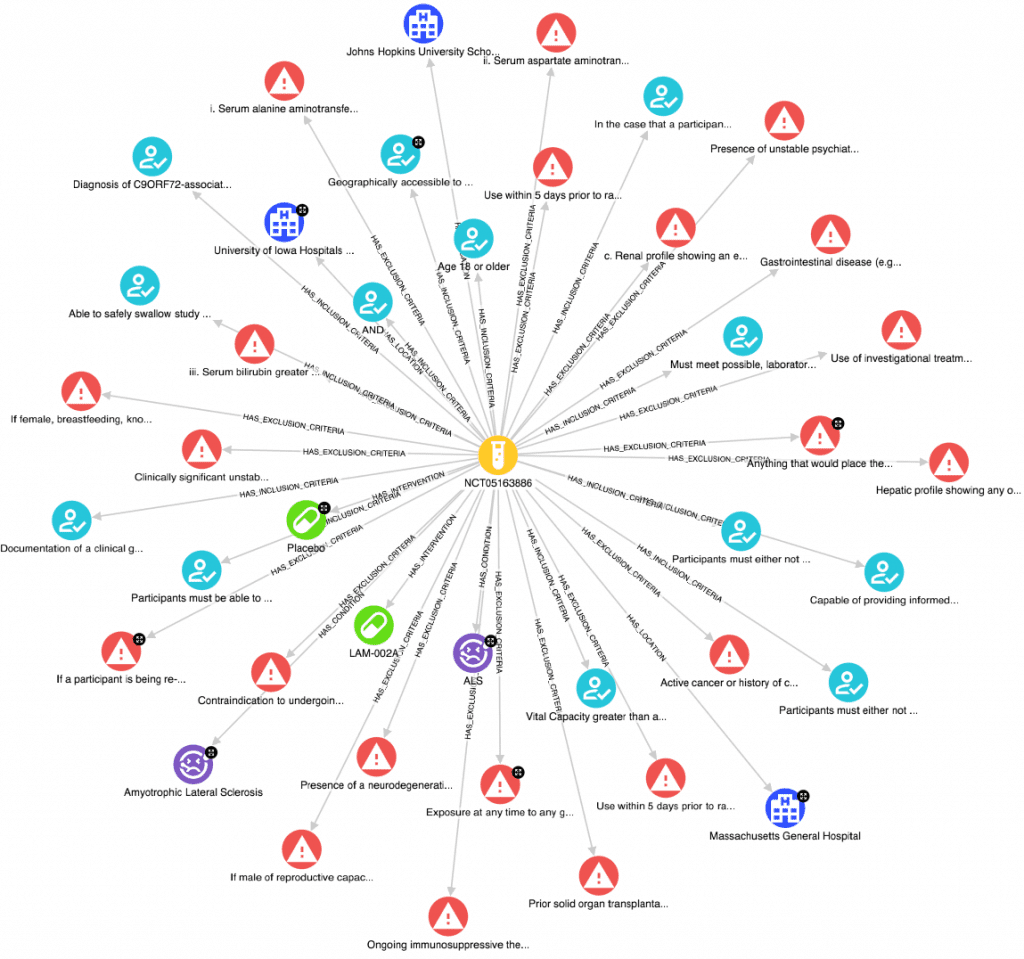
While it appears our pipeline accomplished our goal of ingesting clinical trial data into our knowledge graph, if you look closely you might also notice we have some opportunities to improve some of our data transformations. Specifically, our use of regular expressions to parse the unstructured eligibility criteria into inclusions and exclusions has resulted in a few criteria that need further cleaning, work we can easily iterate on and add as step(s) to our ETL process above in Hume.
Leveraging Graph Algorithms in Graph ETL
Graphs provide unique capabilities that are inherent in their recognition that relationships between data objects are first-class citizens that enhance data interpretation. Relationships modeled in a graph database can be used in graph-specific algorithms such as PageRank, Betweenness Centrality, Closeness Centrality, Degree Centrality, Louvain, and many more.
As an example, the fairly common PageRank graph algorithm measures the importance of nodes contained in a graph. A logical next step for us would be to use the PageRank algorithm to better understand which clinical sites might be good candidates for future clinical studies.
In the context of Neo4j ETL, we would simply expand our Hume pipeline and use a Cypher language component to call Neo4j’s graph data science (GDS) library to compute the PageRank score for each node. Then we would write the score back to each node in the database for output and analysis.
Interested in other articles on graph algorithms, check out this one on betweenness centrality, and another on graph traversal algorithms.
Conclusion
Graph ETL has some common ground with traditional ETL, but the nature of this particular database requires many more specific capabilities to drive out the value of the graph, not the least of which is implementing powerful graph data science algorithms. When it comes specifically to Neo4j ETL, while there are a variety of code-based and other ETL options mentioned above, the Hume platform is the most effective for quickly creating the ETL integrations required to create applications and do deep and uniquely meaningful analyses on connected data.
Read here for more specifics on clinical data trial analytics, and click on these links for more on the related clinical trials Streamlit application (Streamlit tutorial), and here for clinical trial data quality, as well as this article on patient journey mapping.
Graphable helps you make sense of your data by delivering expert data analytics consulting, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
Still learning? Check out a few of our introductory articles to learn more:
- What is a Graph Database?
- What is Neo4j (Graph Database)?
- What Is Domo (Analytics)?
- What is Hume (GraphAware)?
Additional discovery:
- Hume consulting / Hume (GraphAware) Platform
- Neo4j consulting / Graph database
- Domo consulting / Analytics - BI
We would also be happy to learn more about your current project and share how we might be able to help. Schedule a consultation with us today. We can also discuss pricing on these initial calls, including Neo4j pricing and Domo pricing. We look forward to speaking with you!
Graphable helps you make sense of your data by delivering expert analytics, data engineering, custom dev and applied data science services.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we have deep expertise in Financial Services, Life Sciences, Security/Intelligence, Transportation/Logistics, HighTech, and many others.
Thriving in the most challenging data integration and data science contexts, Graphable drives your analytics, data engineering, custom dev and applied data science success. Contact us to learn more about how we can help, or book a demo today.
We are known for operating ethically, communicating well, and delivering on-time. With hundreds of successful projects across most industries, we thrive in the most challenging data integration and data science contexts, driving analytics success.
Contact us for more information: